1. Numpy
- 고성능의 수치계산을 위해 제작된 라이브러리
- 벡터 및 행렬 연산에 있어서 매우 편리한 기능을 제공
1) Numpy import해오기
- import numpy as np
: numpy를 np로 호출

2) np. array(), dtype, np.arrange()
- np.array(): 배열 생성
- .dtype: 데이터 타입 확인
- np.arrange(start=, stop=, step=): 첫값, 끝값, 간격을 설정하고 배열 만들기


3)배열의 사칙연산, 인덱싱

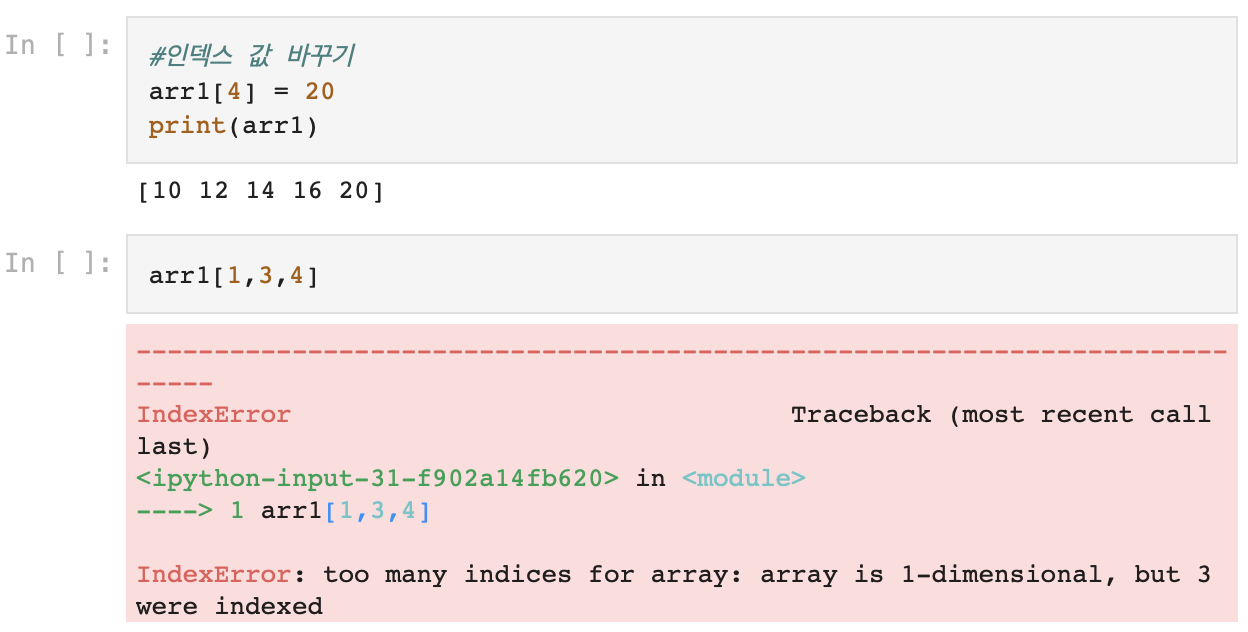
4) 배열에서 인덱스 범위만큼 뽑아보기(슬라이싱)

5) 다차원 배열 만들기(차원변경)_reshape()
- .reshape(2, 5, 1) : 2개의 행에 5개씩 1개간격으로 배치
- .reshape(-1, 5): -1: '행 제한없이' 요소들을 5개씩 만들어 붙여줌

2. Pandas
- 데이터 분석을 위한 필수 라이브러리
- 데이터를 쉽게 확인할 수 있는 형태로 불러옴
- 대용량 데이터를 보다 안정적이고 빠르게 처리할 수 있음
- Series와 DataFrame 두가지 형태로 나눌 수 있음
1) Pandas import해오기
- import pandas as pd
: pandas를 pd로 호출

2) pd.Series(), pd.DataFrame()
- .series(): 1차원 배열의 인덱스와 값으로 구성됨
- .DataFrame(): 시리즈를 표 형태(데이터프레임 형태)로 묶어줌

3) .DataFrame에 데이터 넣어보기
- col, val를 직접 설정해서 DataFrame 씌우기
- 딕셔너리를 만들어서 DataFrame 씌우기
- data, column, index 직접 설정해서 DataFrame 씌우기



4) 평균(mean), 표준편차(std), 통계적 분포(describe)
- .mean() : 데이터프레임 평균 구하기
- .std() : 데이터프레임 표준편차 구하기
- .describe(): 데이터프레임의 통계적 분포 보기


5) 데이터프레임 데이터 추출_ .loc, .iloc
- .loc[]: 찾는 값을 직접 입력해서 데이터 찾기
ex) df_sales.loc["2022"] -> "2022"행의 데이터 값 출력
- .iloc[]: 인덱스를 입력해서 데이터 찾기
ex) df_sales.iloc[2:4, 0] -> 2~3행, 0열의 데이터값 출력



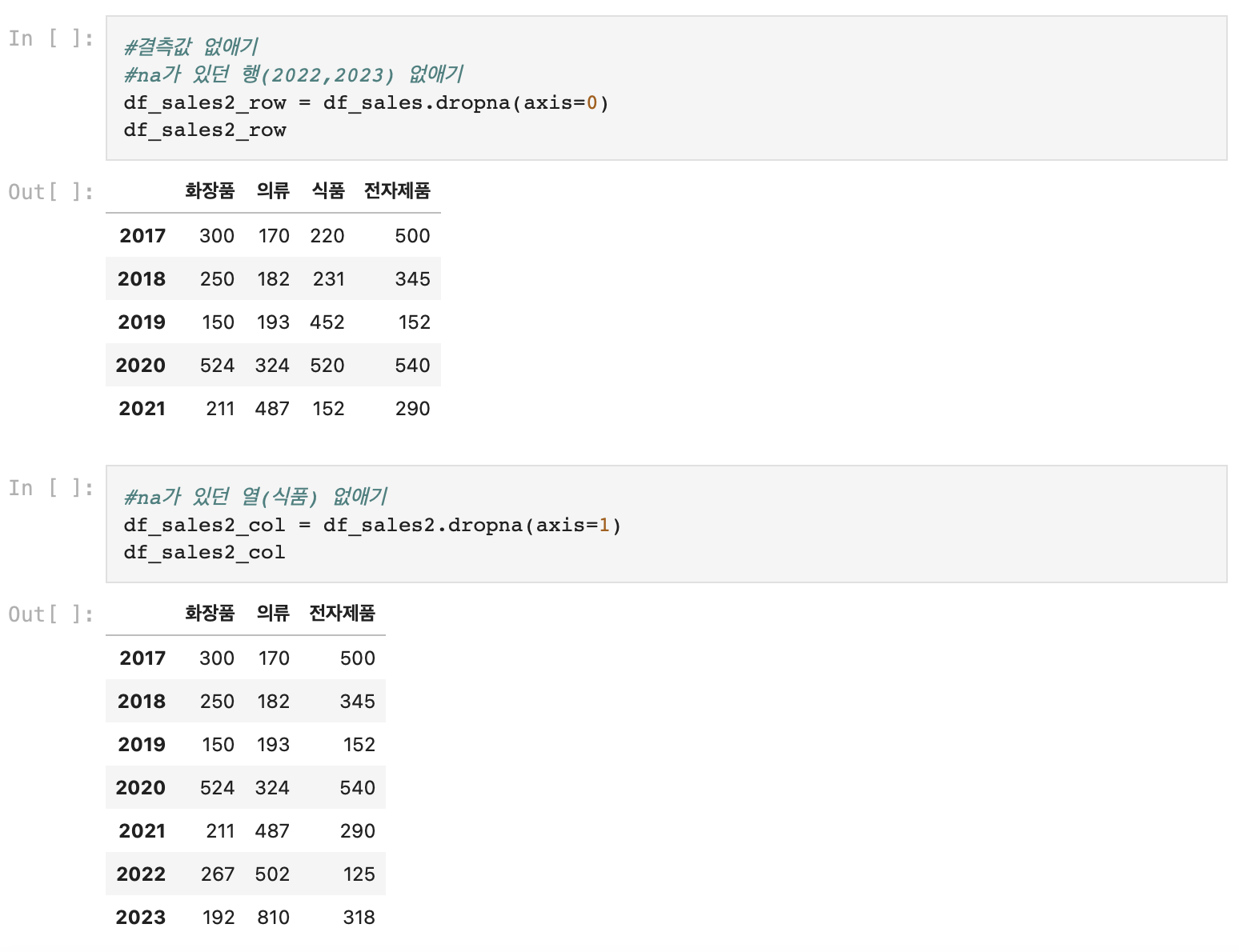
6) 결측값 확인, 삭제, 대체_isnull(), dropna(), fillna()
*결측값 확인
- .isnull() : True, False값으로 결측값 확인
- .isnull.sum(): 결측값 갯수 세기

*결측값 삭제
- .dropna(axis = 0): 결측값이 있는 행 없애기
- .drupna(axis = 1): 결측값이 있는 열 없애기
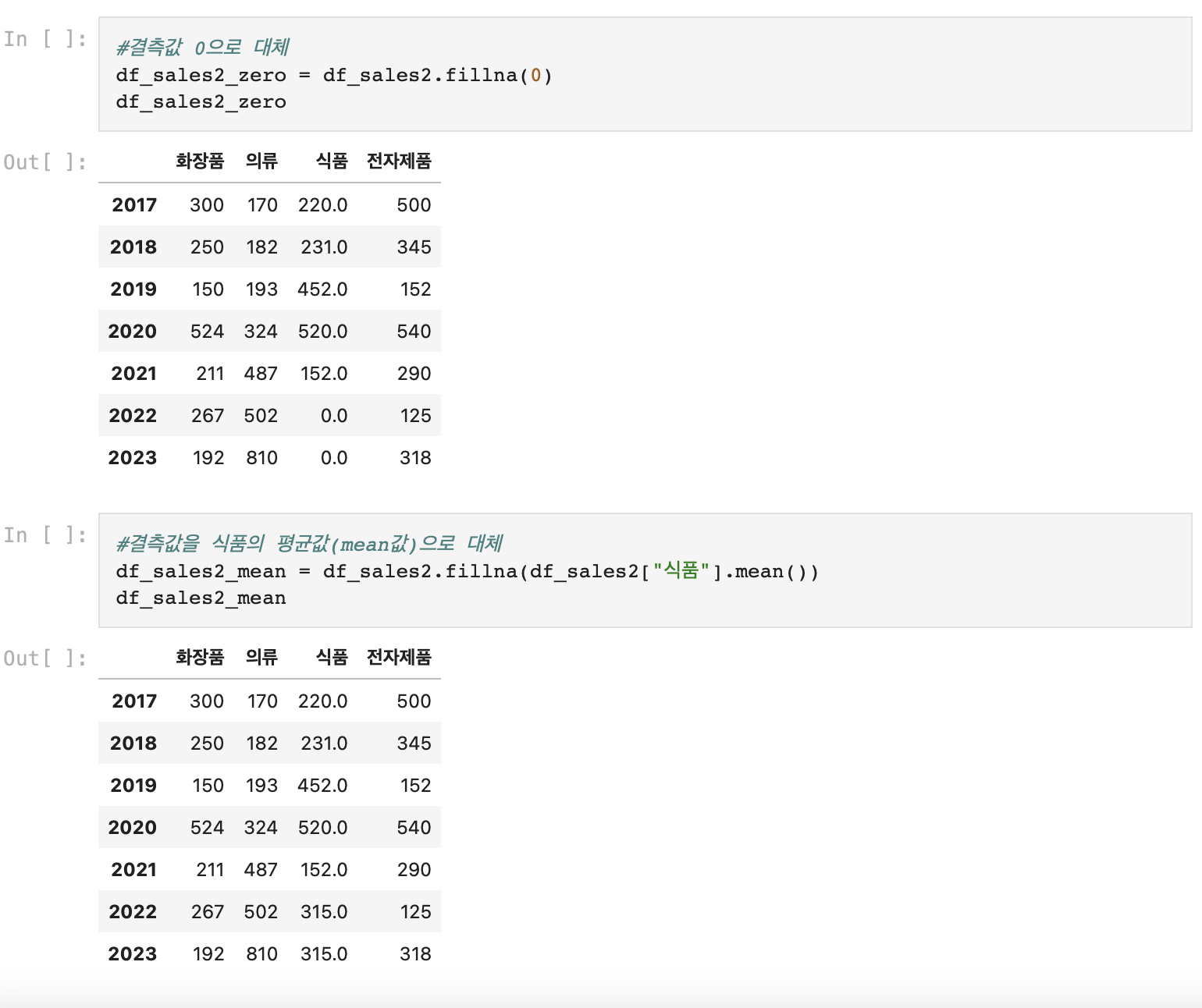
* 결측값 대체
- .fillna(0): 결측값을 0으로 대체
- .fillna(data.mean()): 결측값을 해당 데이터값의 평균값으로 대체
'Python > Basic Data Analysis' 카테고리의 다른 글
| [Python Data Analysis]데이터 분할&합치기, 산점도(Scatter), 조건에 따른 평균/분산/표준편차, 왜도&첨도 (0) | 2023.01.11 |
|---|---|
| [Python Data Analysis]IQR을 사용하여 이상치 제거하기_Boxplot, Histogram (0) | 2023.01.10 |
| [Python Data Analysis]반복문 코드리뷰(while, for) (0) | 2023.01.09 |
| [Python Data Analysis]파이썬 기초문법(2)_조건문(if), 반복문(while, for), def만들기 (2) | 2023.01.08 |
| [Python Data Analysis] 파이썬 기초문법(1)_변수, 타입, 인덱스, 리스트, 튜플, 딕셔너리, 세트 (0) | 2023.01.08 |