* 분류모델 평가
1) 오분류표

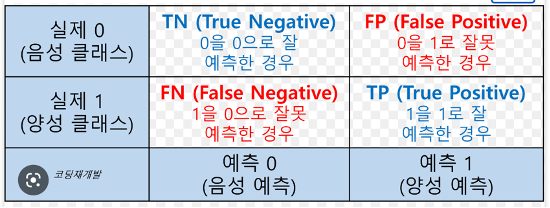

- Accuracy(정확도) = TP + TN / TP + FN + FP + TN => 분자가 모두 T
- Error Rate(오분류율) = FP + FN / TP + FN + FP + TN (1 – Accuracy) => 분자가 모두 F
- Sensitivity(민감도) & Recall(재현율) = TP / P => 두개의 식이 같음
- Specificity(특이도) = TN / N => sensitivity의 반대편
- Precision(정밀도) = TP / TP + FP => 모두 P에 관한 것
- F1 score = 2 * precision * recall / precision + recall => 더하기가 아래로(분모로) 간다라고 생각
*accuracy, F1 score 모두 1에 가까울 수록 좋은 지표
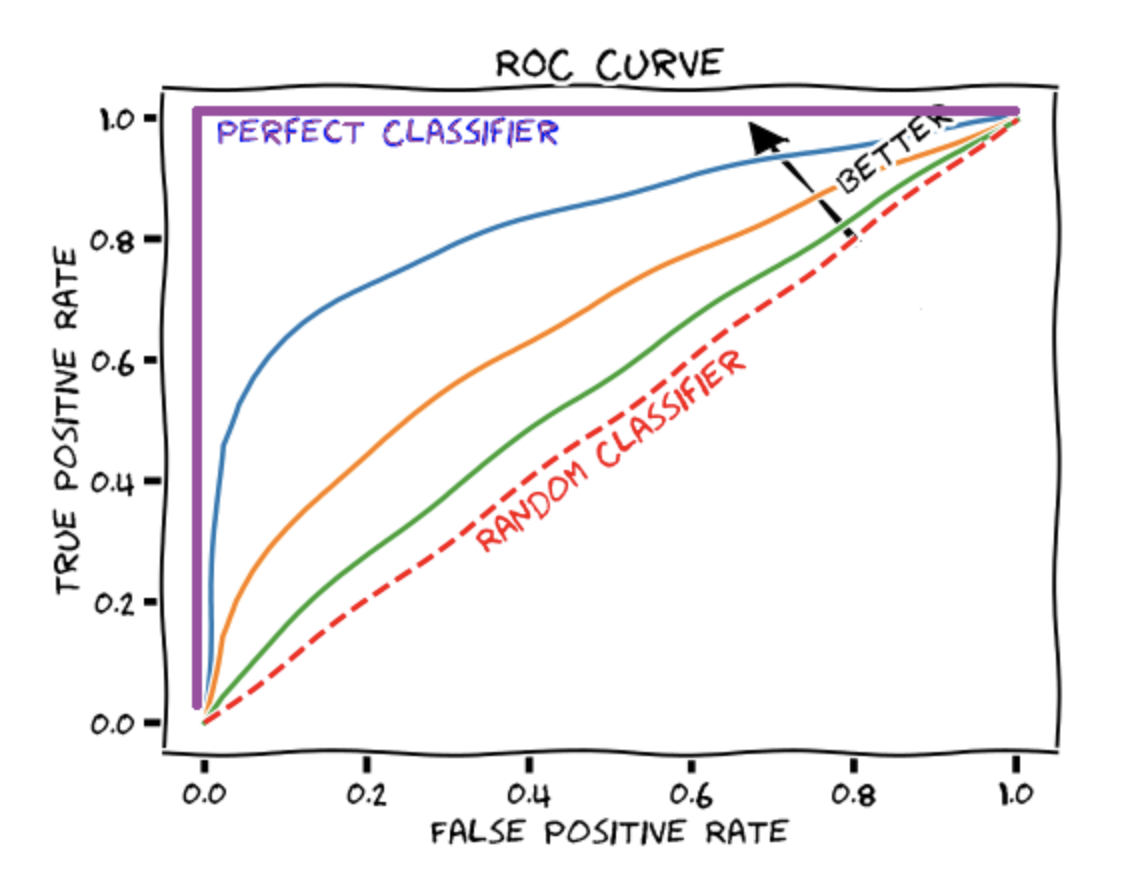
2) ROC 곡선
- 가로축을 FPR(1-특이도)값으로 두고, 세로축을 TPR(민감도)값으로 두어 시각화 한 그래프
- 그래프가 완쪽 상단에 가깝게 그려질수록 올바르게 예측한 비율이 높음을 의미
- AUROC: ROC곡선 아래의 면적. 1에 가까울수록 모형의 성능이 좋음
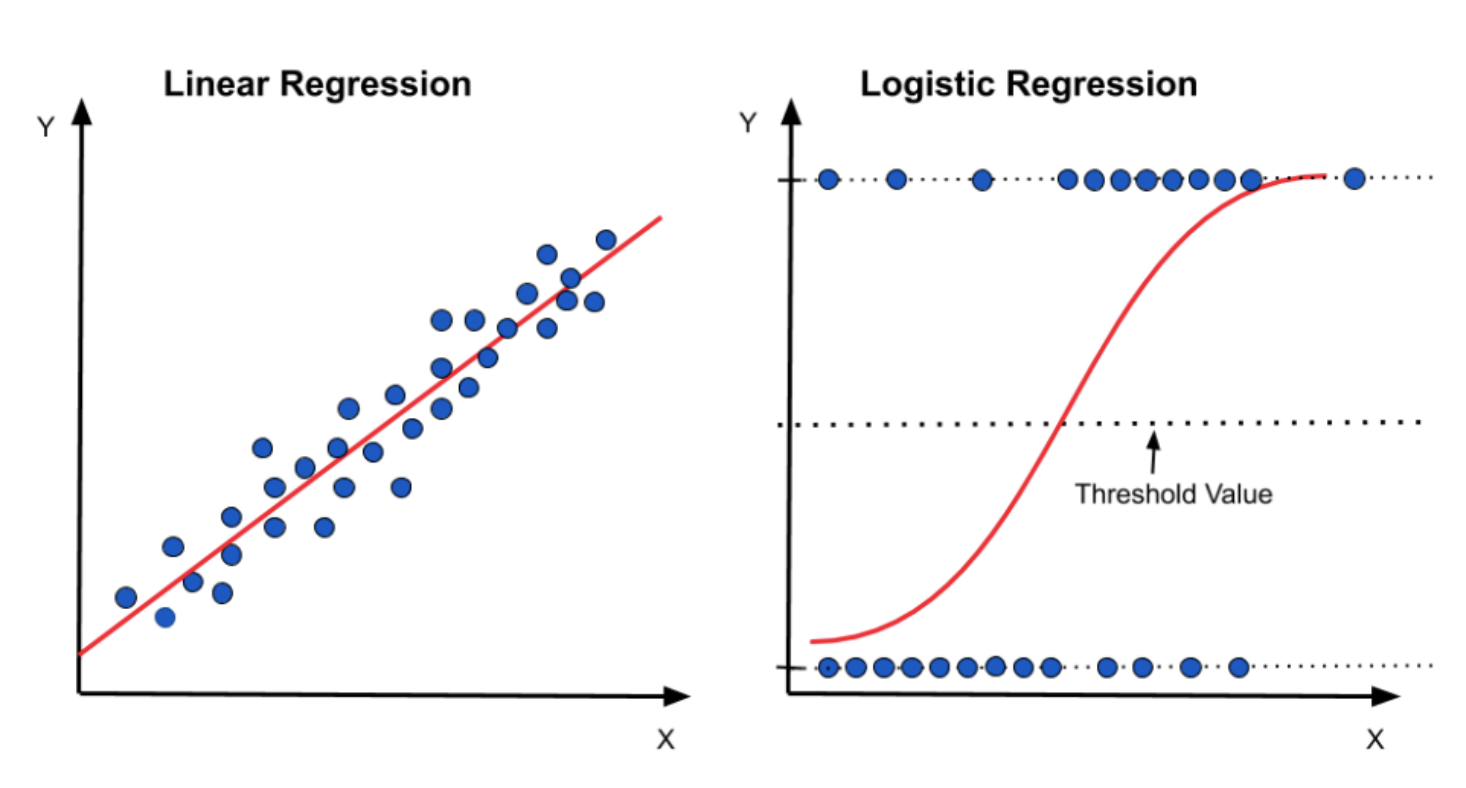
* 로지스틱 회귀
- y(종속변수)가 범주형인 경우 적용되는 회귀 분석 모델
- 새로운 독립변수가 주어질 때 종속변수의 각 범주에 속할 확률이 얼마인지를 추정하여, 추정 확률을 기준치에 따라 분류
- 오즈비: 오즈는 성공할 확률이 실패할 확률의 몇 배인지를 나타내는 확률, 오즈비는 오즈의 비율을 의미
- 다항 로지스틱 회귀: 로지스틱 회귀 분석과 유사하지만 종속변수가 두 개의 범주로 제한되지 않음(다항으로 클래스가 이루어짐)
cf) 회귀모형과 분류모형 구분
1) 회귀모형
- y= 연속형(숫자)
- R^2 높을수록
- MSE, AIC 낮을수록 좋음 (AUC와 헷갈리지 않기!)
2) 분류모형
- y= 이산형(집단)
- 어느 집단으로 분류를 할 것인가의 문제
-> x만 보고(어떠한 특성만 보고도) y가 어떤 집단에 속할 것인가를 추정
-> 맞을 수도, 틀릴 수도 있음
- Accuracy, F1, ROC, AUC
- ‘로지스틱 회귀분석’- R^2(회귀모형)이 나오지만 최종적으로는 ‘분류모형’
-> 최종결과가 ‘0 또는 1’로 나오기 때문에
* 로지스틱 회귀, 다항 로지스틱 회귀 코딩
1. 데이터 확인
- info(), describe(), isnull().sum()을 통해 전체적인 데이터 파악
- columns를 통해 변수 확인


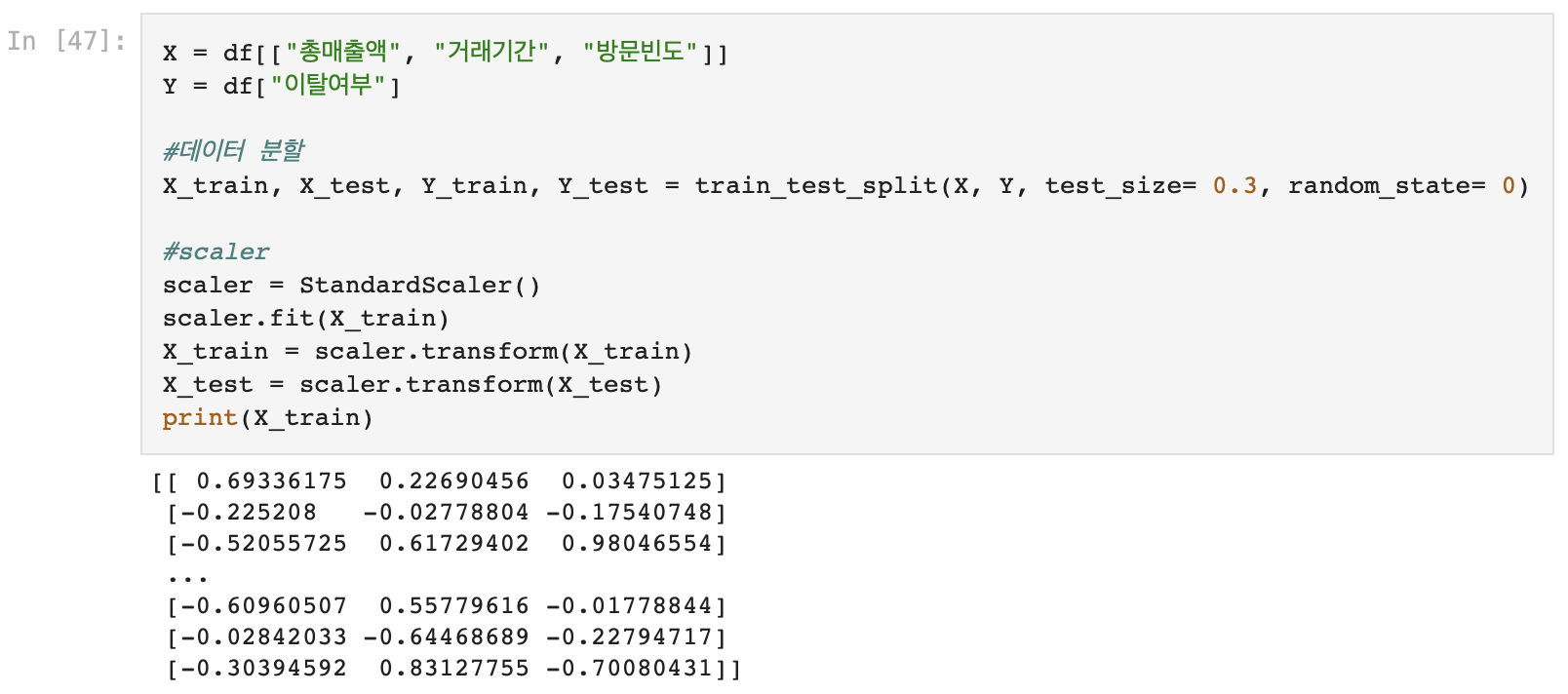
2. 데이터 분할, Scaler적용
- test size= 0.3(30%)로 X, Y 데이터 분할
- 연속형 데이터('총매출액', '거래기간', '방문빈도') -> StandardScaler()적용
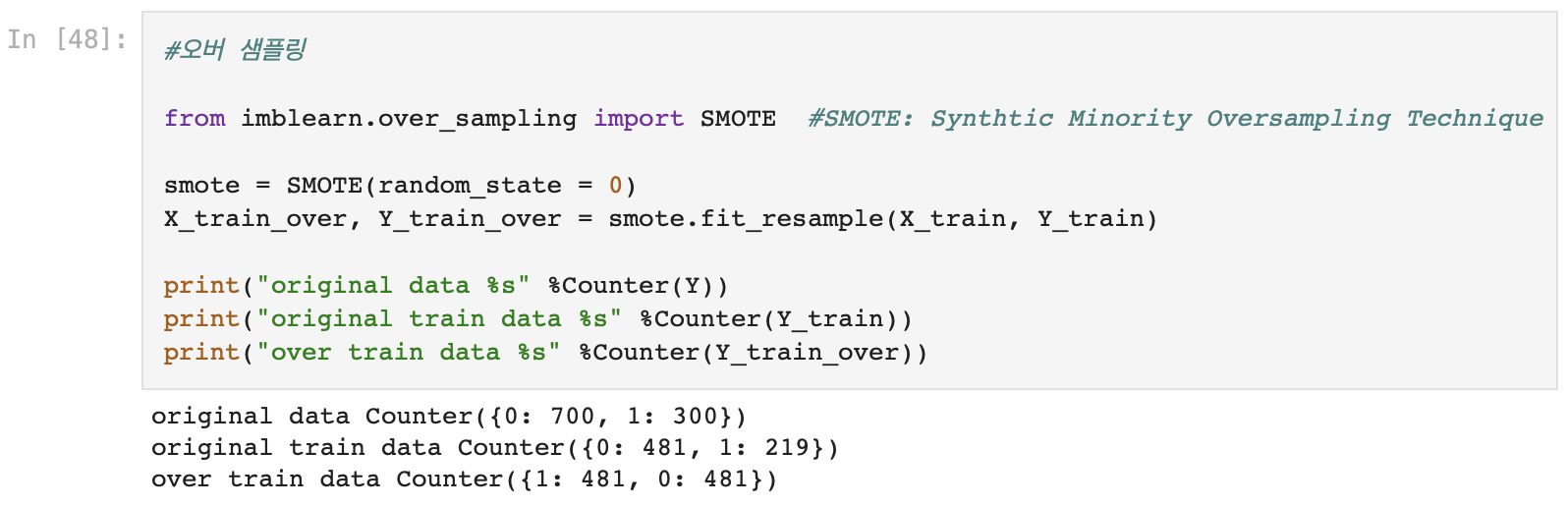
3. 오버 샘플링
- Y에 SMOTE 적용
- 데이터 밸런싱을 하는 이유?
- 종속 변수가 동일한 비율의 클래스를 가지고 있지 않고 특정 클래스가 높은 비율을 차지하고 있는 경우, 데이터 불균형 문제를 해결하기 위해
4. 로지스틱 회귀분석
- LogisticRegression(C = 1, Random_state = 0)
- 'C = 1' -> 기준값(너무 높거나 낮으면 모델 성능 떨어짐)
- 결과값 도출: R2, Classification_Report(f1-score), coefficient
- f1score = precision * recall / precision + recall

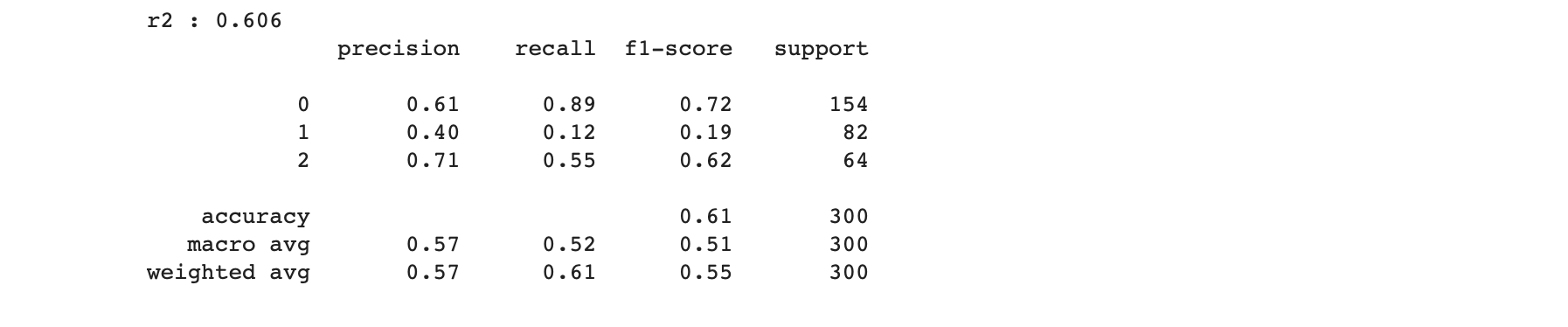
5. 다항 로지스틱 회귀분석
- Y('구매금액대')는 0, 1, 2의 세가지 클래스로 이루어져 있음
- X의 연속형, 범주형 변수 각각 StandardScaler, OneHotEncoder 적용
- LogisticRegression(random_state = 0, C = 0.1, solver = 'newton-cg', multi_case = 'multinomial')
- 과적합 방지하기 위해 C = 0.1로 설정 (기본값: C = 1)
- 'solver' = 어떤 가중치를 사용해서 해결할 것 인가; 'lbfgs', 'liblinesr', 'sag', 'saga' 등
- 결과값 도출: R2, Classification_Report

'Python > Machine Learning' 카테고리의 다른 글
| [Python ML]서포트 벡터 머신(SVM)_SVC/SVR, 나이브 베이즈(Naive Bayes)_GaussianNB/BayesianRidge (0) | 2023.01.20 |
|---|---|
| [Python ML]K-최근접이웃(K-NN), 의사결정나무(Decision Tree) (0) | 2023.01.18 |
| [Python ML]규제기법(Regularization)_릿지(Ridge), 라쏘(Lasso), 엘라스틱 넷(Elastic-Net) (1) | 2023.01.16 |
| [Python ML]선형 회귀분석(Linear Regression Analysis) (0) | 2023.01.15 |
| [Python ML]변수 선택(일변량 통계기반/모형기반), 데이터 밸런싱(언더 샘플링/오버 샘플링(SMOTE)) (0) | 2023.01.15 |