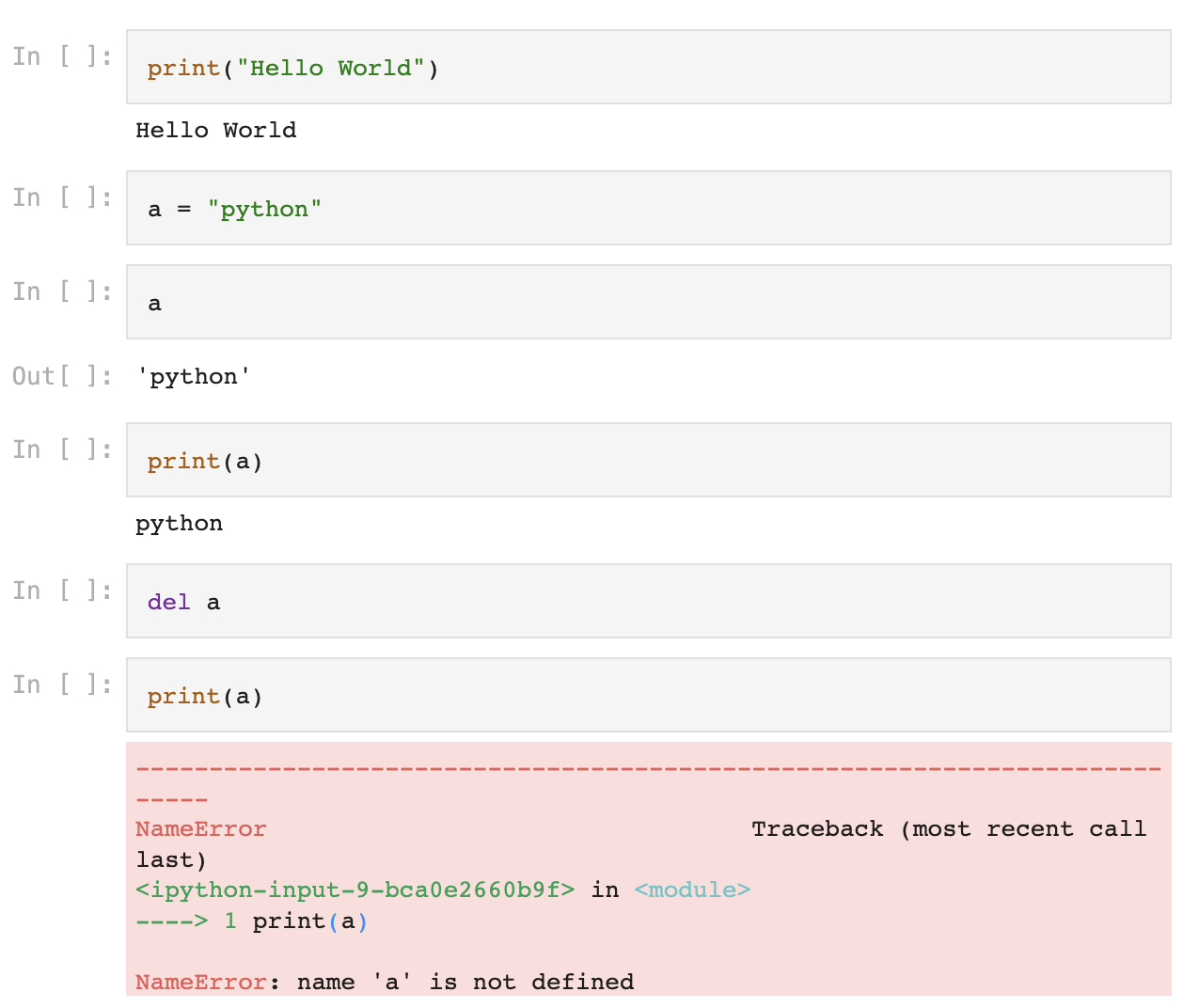
1. 변수a 생성, 삭제(del)
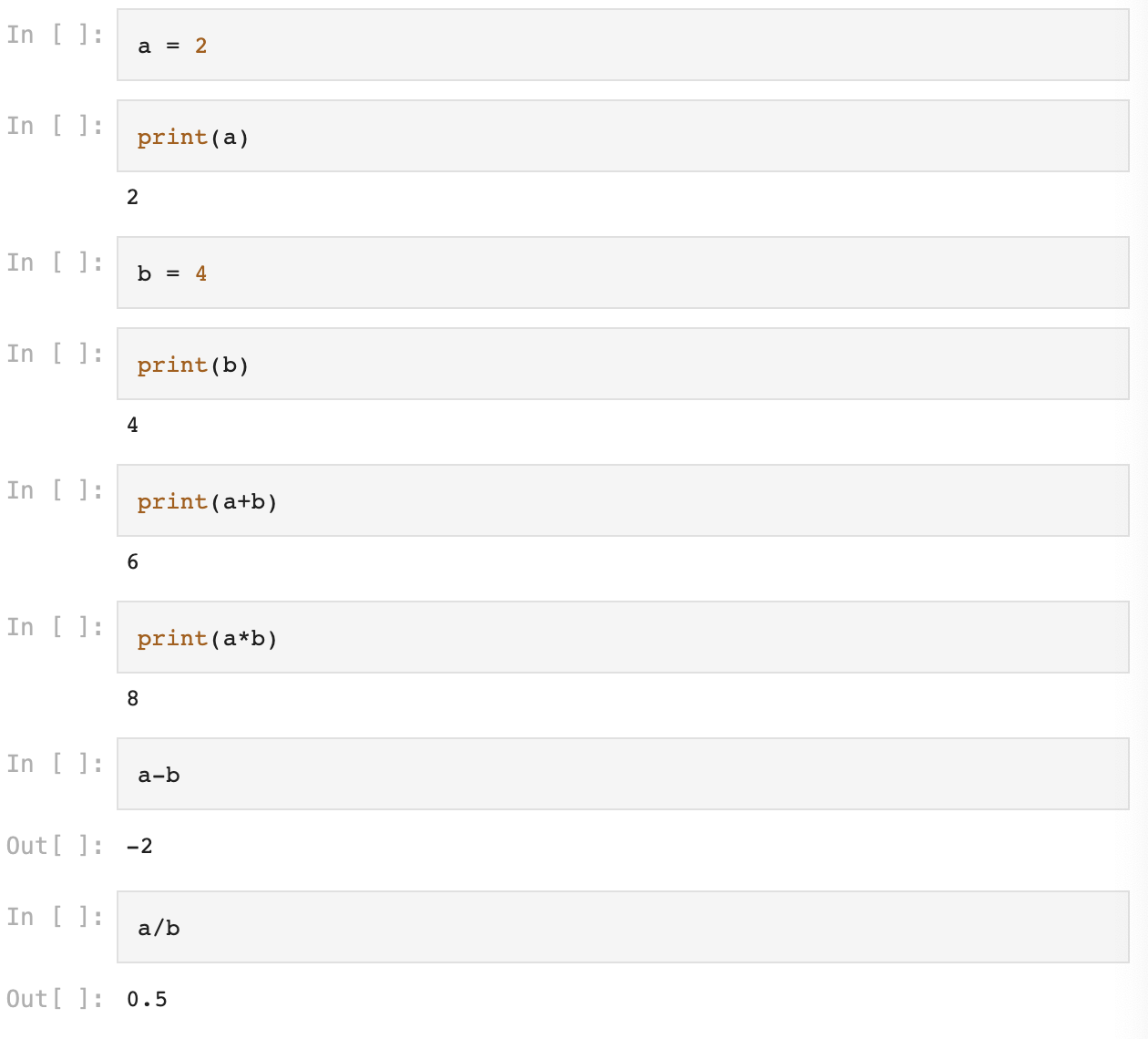
2. 변수의 사칙연산
3. 변수의 타입(Type)
- int: 정수
- float: 상수
- str: 문자열


4. 제곱, 루트, 몫, 나머지
- 제곱: 3**20 = 3486784401 (3의 20승)
- 루트: 3**0.5 = 1.73205.. (루트3)
- 몫: 13//4 = 3 (13÷4의 몫)
- 나머지: 13%4 = 1 (13÷4의 나머지)

5. 문자열 특징
- 문자열을 " "로 묶었을 때에는 안에 ' 를 써도 출력되지만, ' '로 묶었을 때에 '를 출력하려면 앞에 \ 를 붙여 에러를 막음.
- \n : enter키 삽입
- 문자열 합치기: 문자열 + 문자열
- 문자열 n회 반복: 문자열 * n

6. 문자열의 인덱스 & 범위 & 관련함수
- S / o / h / y / u / n / / K / i / m 에서 (*공백도 인덱스에 포함)
#0 1 2 3 4 5 6 7 8 9 (S부터 #0 시작)
#-10 -9 -8 -7 -6 -5 -4 -3 -2 -1 (m부터 역순으로 #-1 시작)
- [:6] = 인덱스 0~5까지
- [6:] = 인덱스 6~끝까지

- len() : 총 길이(갯수)를 세어주는 함수
- .count("a"): a의 갯수를 세어주는 함수
- .find("a"): a의 인덱스를 찾아주는 함수

- a.join(): "SohyunKim" 각 인덱스 사이에 공백 두기
- .upper(): 모두 대문자로 바꾸기
- .lower(): 모두 소문자로 바꾸기
- .strip(a): 문자열 양 옆의 공백 지우기 (a = " " , 공백으로 지정했음)
- .lstrip(a): 문자열 왼쪽의 공백 지우기
- .rstrip(a): 문자열 오른쪽의 공백 지우기

- .replace("A", "B") : A를 B로 바꾸기(대체하기)
- .split( ): 공백을 기준으로 문자열을 나누기

7. 리스트(list) & 튜플(tuple)
* 리스트(list)
- [ ]안에 값을 넣음
- 리스트 안의 요소들 수정 가능(변수를 자주 변경하고 싶을 때 사용)
* 튜플(tuple)
- ( )안에 값을 넣음
- 튜플 안의 요소들은 수정 불가(replace를 안하고 싶을 때 사용; 변하는 수가 없을 때)


- del a[n]: 리스트a의 인덱스 n번째 값 지우기
- .append(): 리스트에 값 추가하기
- .sort(): 오름차순 정렬
- .reverse(): 내림차순 정렬
- .index(n): n의 인덱스 값 찾기

- .insert(n, a): 인덱스n번째에 a값 넣기
- .remove(a): a값 리스트에서 제거하기
- .pop(n): 해당 인덱스를 리스트 안에서 뽑기(없애기)
- .count(n): 리스트 안 n의 갯수
- len(a): 리스트a 안 값의 갯수

8. 딕셔너리(Dictionary)
- 구조: 단어(key), 설명(값)
- a = {"키" : "값", "값", "값", ...., "키": "값", "값", ...}









9. 세트(Set)
- 문자열, 리스트 안의 중복되는 요소들 제거하여 각 요소들 하나씩만 출력됨




10. %d, %f, %s 대입하기
- %d: 정수값 대입
- %f: 상수값 대입
- %s: 문자열 대입


'Python > Basic Data Analysis' 카테고리의 다른 글
| [Python Data Analysis]데이터 분할&합치기, 산점도(Scatter), 조건에 따른 평균/분산/표준편차, 왜도&첨도 (0) | 2023.01.11 |
|---|---|
| [Python Data Analysis]IQR을 사용하여 이상치 제거하기_Boxplot, Histogram (0) | 2023.01.10 |
| [Python Data Analysis]Numpy, Pandas_배열, Series, DataFrame, 결측값 (0) | 2023.01.10 |
| [Python Data Analysis]반복문 코드리뷰(while, for) (0) | 2023.01.09 |
| [Python Data Analysis]파이썬 기초문법(2)_조건문(if), 반복문(while, for), def만들기 (2) | 2023.01.08 |