728x90
1) 필요 패키지 불러오기
- pandas, train_test_split(데이터 분할)

2) 데이터 불러오고 결측값 제거
- dropna()는 전체 데이터에 적용하기 (X, Y 따로따로 했다가 행 수가 안맞아서 error가 계속 났다..)
- isnull.sum(): 결측값 제거 확인하기

3) 데이터 분할, 통계기반 변수선택



4) Y에 로그 적용


5) 데이터 분할, 데이터 표준화
- 변수선택에서 연속형 데이터를 가진 변수만 도출되었기 때문에, StandardScaler()적용

6) 선형 회귀분석
- LinearRegression()
- R2 = 0.843 (모델이 평균의 84%정도의 정확도로 설명하고 있다. )
- RMSE= 0.014 (실제값과 예측된 y의 오차가 0.014이다. )


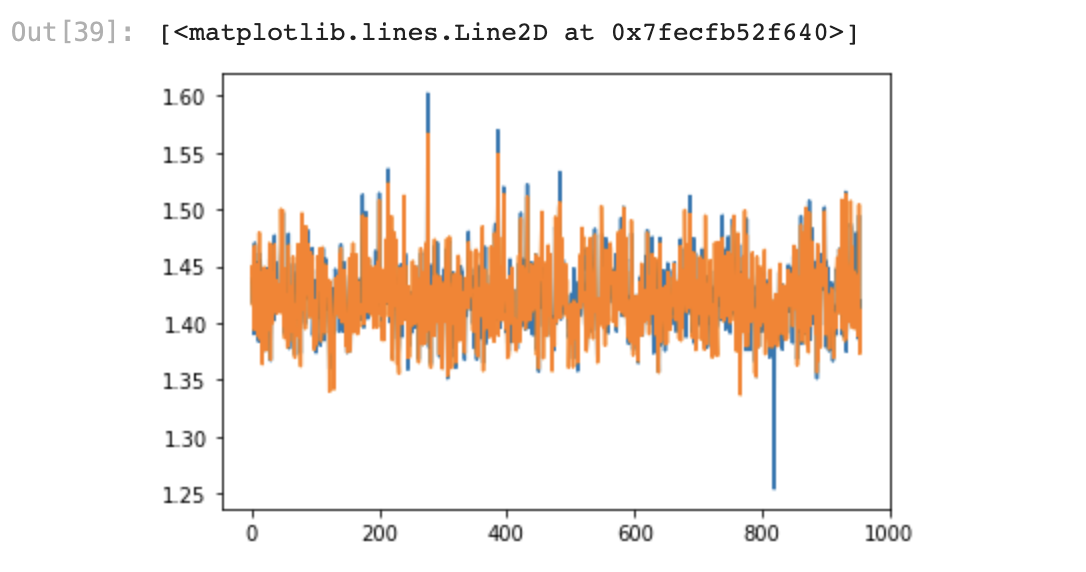
7) 실제값과 예측값 시각화하여 비교

728x90
반응형
'Python > Small Project' 카테고리의 다른 글
| [Python]Galaxy Z Flip·Fold5 소비자 반응 수집(네이버 데이터랩, 빅카인즈 기사, 유튜브 댓글 크롤링&시각화) (1) | 2023.08.15 |
|---|---|
| [Python] 'RFM 분석'을 통해 VIP 고객 선정하기 (1) | 2023.03.31 |
| [Python]LG그램&뉴진스 YouTube M/V 댓글 크롤링 후 텍스트 마이닝 시각화 해보기 (10) | 2023.01.31 |
| [Python ML]KOSIS 통계자료를 활용하여 5가지 모델 성능 비교해보기 (0) | 2023.01.24 |