* KOSIS 국가통계포털
(사이트 소개글)
국가통계포털(KOSIS, Korean Statistical Information Service)은 국내·국제·북한의 주요 통계를 한 곳에 모아 이용자가 원하는 통계를 한 번에 찾을 수 있도록 통계청이 제공하는 One-Stop 통계 서비스입니다. 현재 300여 개 기관이 작성하는 경제·사회·환경에 관한 1,000여 종의 국가승인통계를 수록하고 있으며, 국제금융·경제에 관한 IMF, Worldbank, OECD 등의 최신 통계도 제공하고 있습니다. 쉽고 편리한 검색기능, 일반인들도 쉽게 이해할 수 있는 다양한 콘텐츠 및 통계설명자료 서비스를 통해 이용자가 원하는 통계자료를 쉽고 빠르고 정확하게 찾아보실 수 있습니다.
사이트: https://kosis.kr/index/index.do
KOSIS 국가통계포털
내가 본 통계표 최근 본 통계표 25개가 저장됩니다. 닫기
kosis.kr
1. 필요 패키지, 함수 불러오기


2. 데이터 불러오기
- 나는 KOSIS에서 2019, 2020, 2021년도의 행정구역별 자료를 엑셀에서 합쳐서 구글 드라이브 파일로 불러왔다.
- 행정구역별_ 신혼부부 수, 맞벌이 부부 수, 평균 출생아 수, 1인당 개인소득, 1인당 지역총소득, 1인간_민간소비지출액, 총 가구, 주택소유 가구, 무주택 가구
- 행정구역이 한글로 되어있어 '행정구역별 ID'라는 열을 추가해 행정구역 별로 임의의 수를 지정했다.
- '연도' 열을 추가해 2019, 2020, 2021년으로 지정했다.




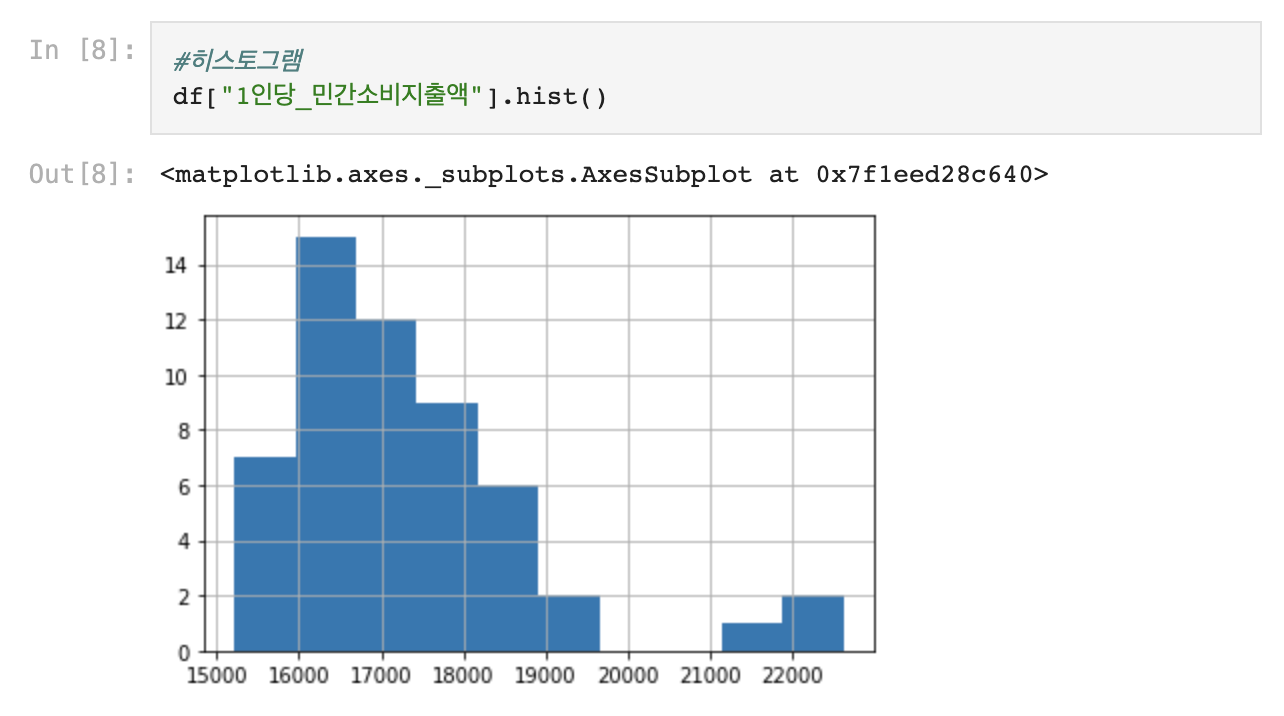
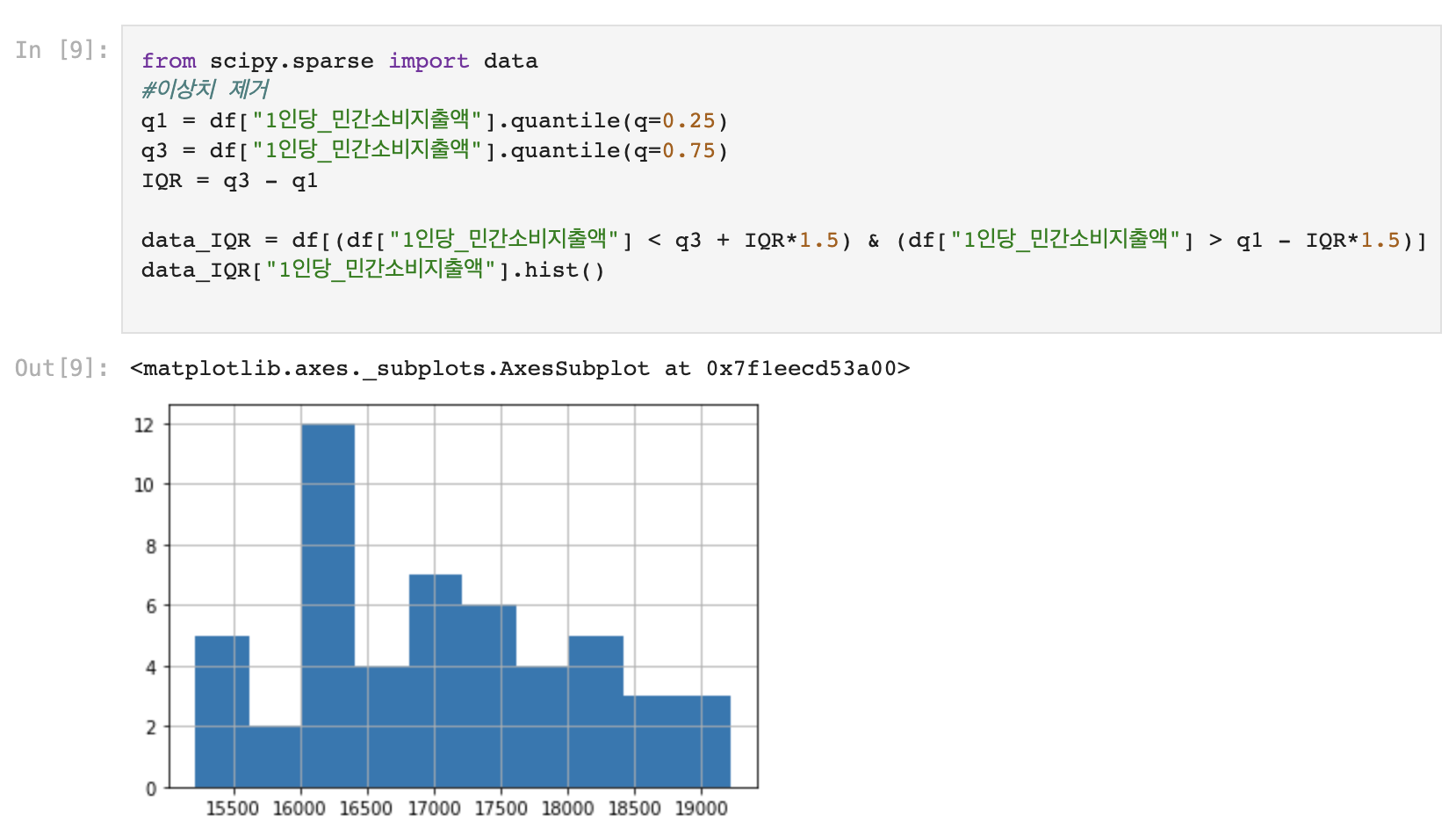
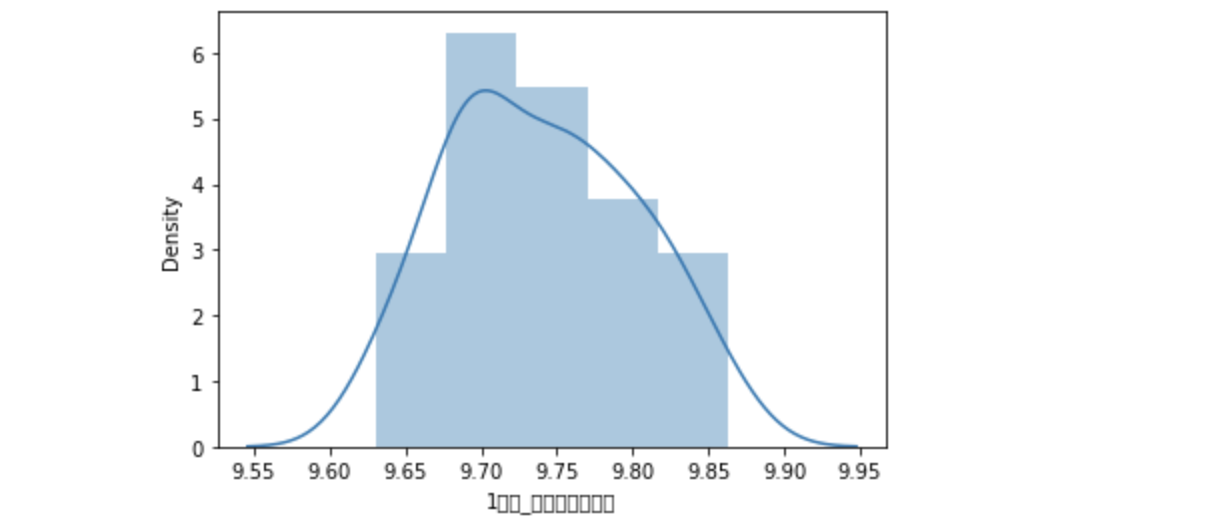
3. 이상치 찾고 제거하기
- Y = '1인당_민간소비지출액'




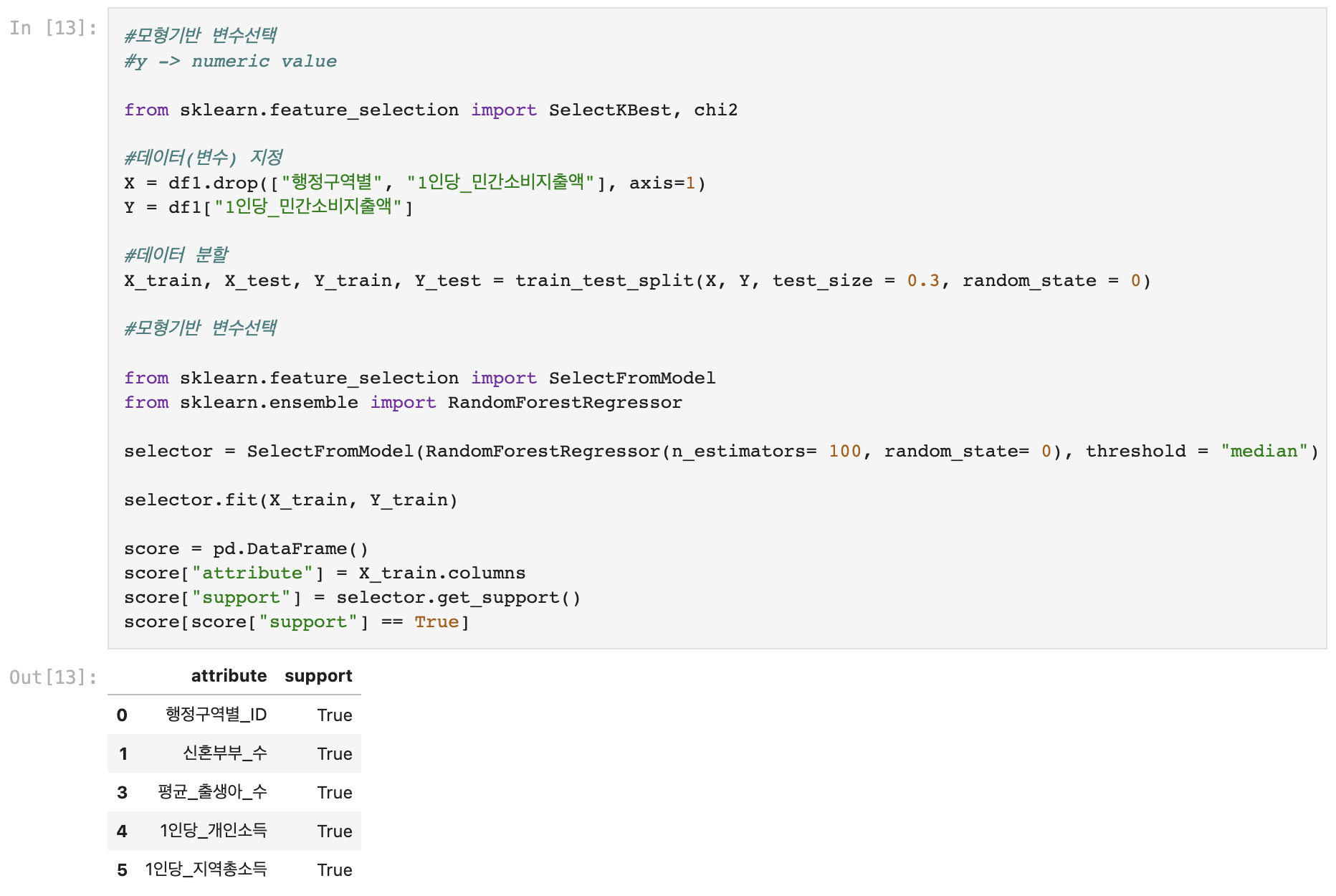
4. 변수 선택 (모형기반)
- Y = '1인당_민간소비지출액' ➡️ 연속형 변수(numeric value)
- X = '행정구역별'(행정구역별_ID와 중복되는 요소), '1인당_민간소비지출액'(y값) drop시킨 모든 변수
- 모형기반 변수선택: SelectFromModel
- 모형(모델): RandomForestRegressor 사용
5. 모델 생성
- 순서: 데이터 분할 ➡️ 데이터 스케일링 ➡️ 모델 생성(KNeighborsRegressor) ➡️ 모델 학습 ➡️ 결과값 확인
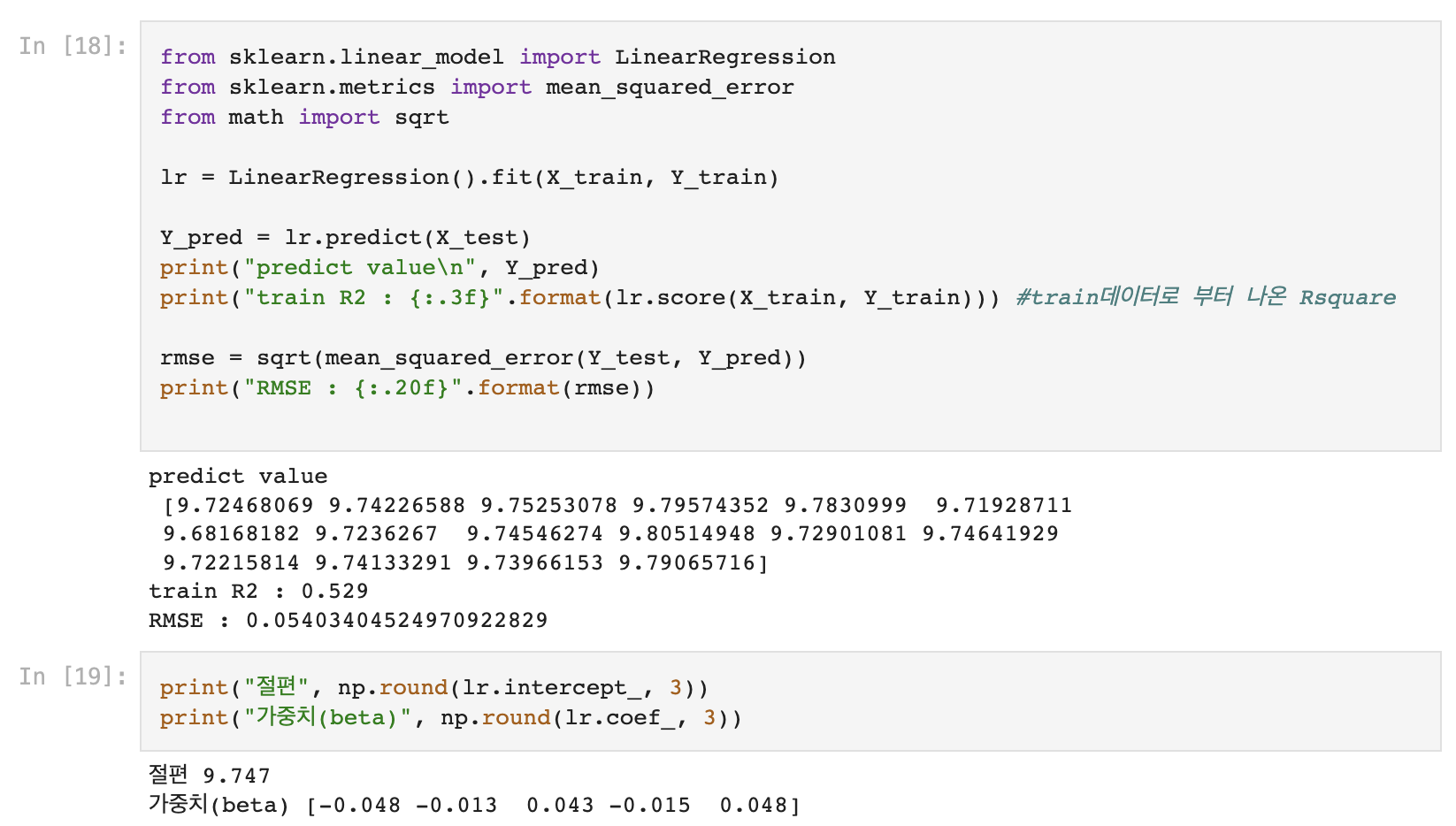
1) 선형 회귀(LinearRegression)

2) K-NN (KNeighborsRegressor)

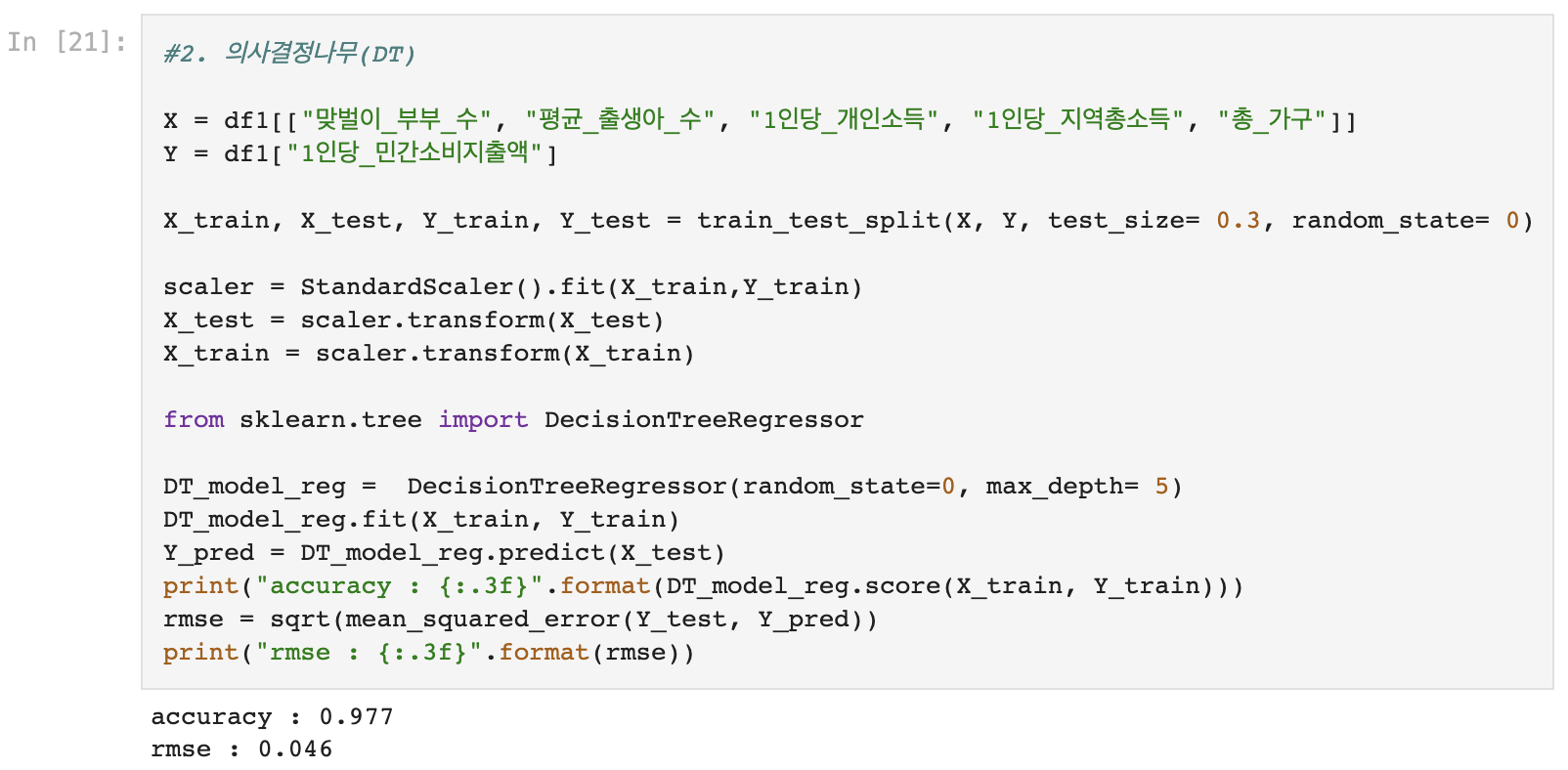
3) 의사결정나무 (DecisionTreeRegressor)


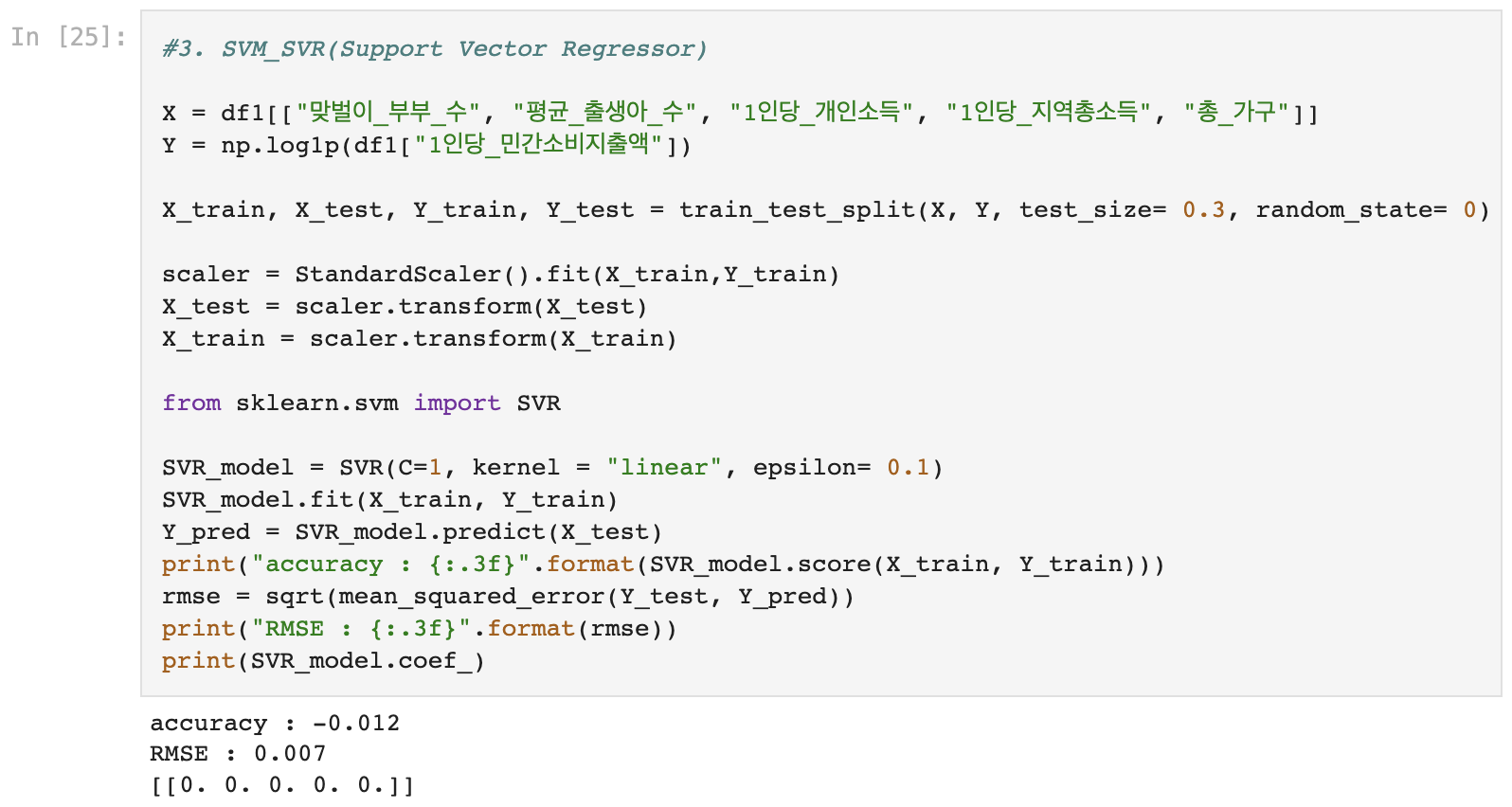
4) SVR (SupportVectorRegressor)
5) 나이브 베이즈 (BayesianRidge)
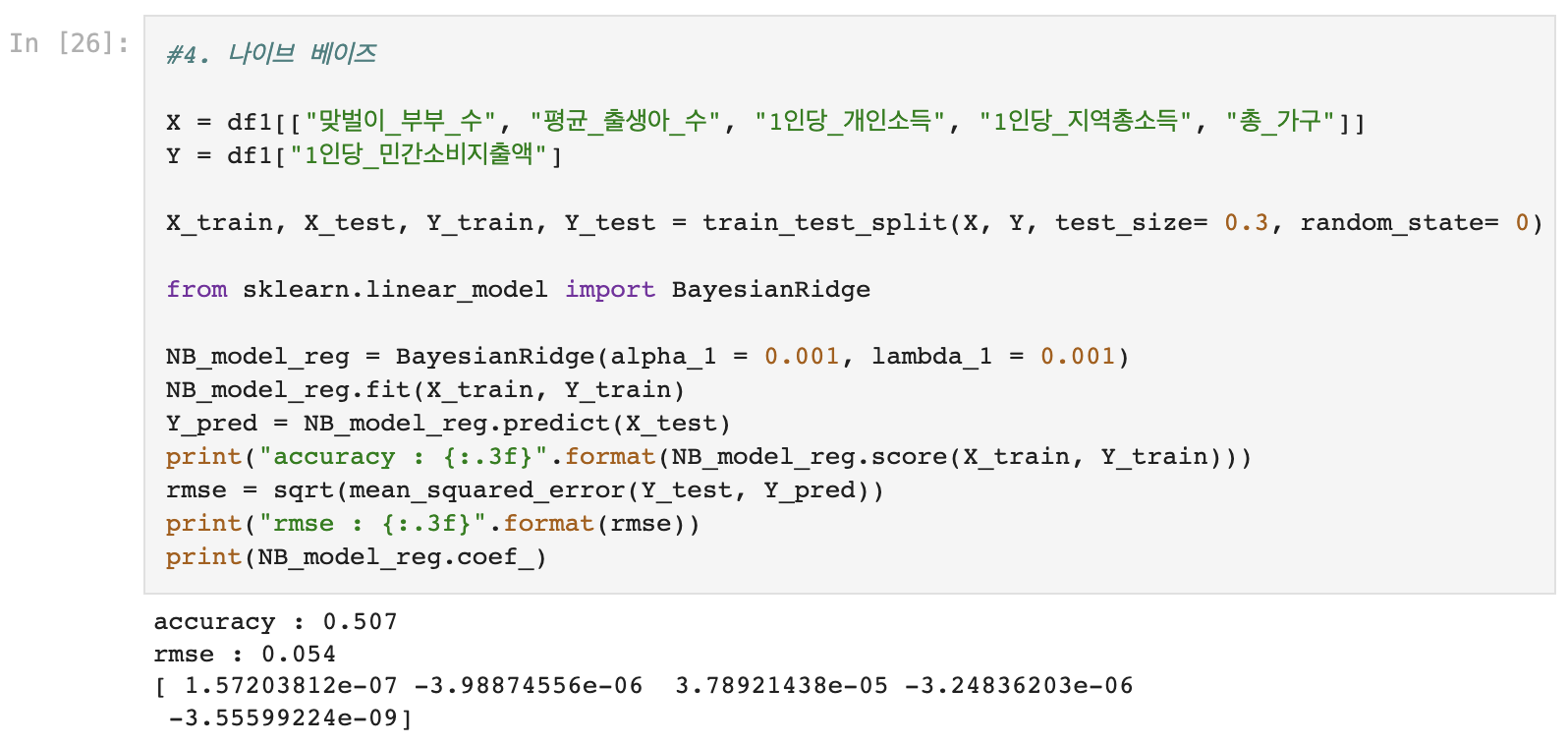
6. 모형 성능 비교
- LinearRegression, K-NN, DecisionTree, Naive Bayes 네가지 모델 비교
- SVR모델은 성능 비교에서 제외 (결과값이 이상하게 나옴)




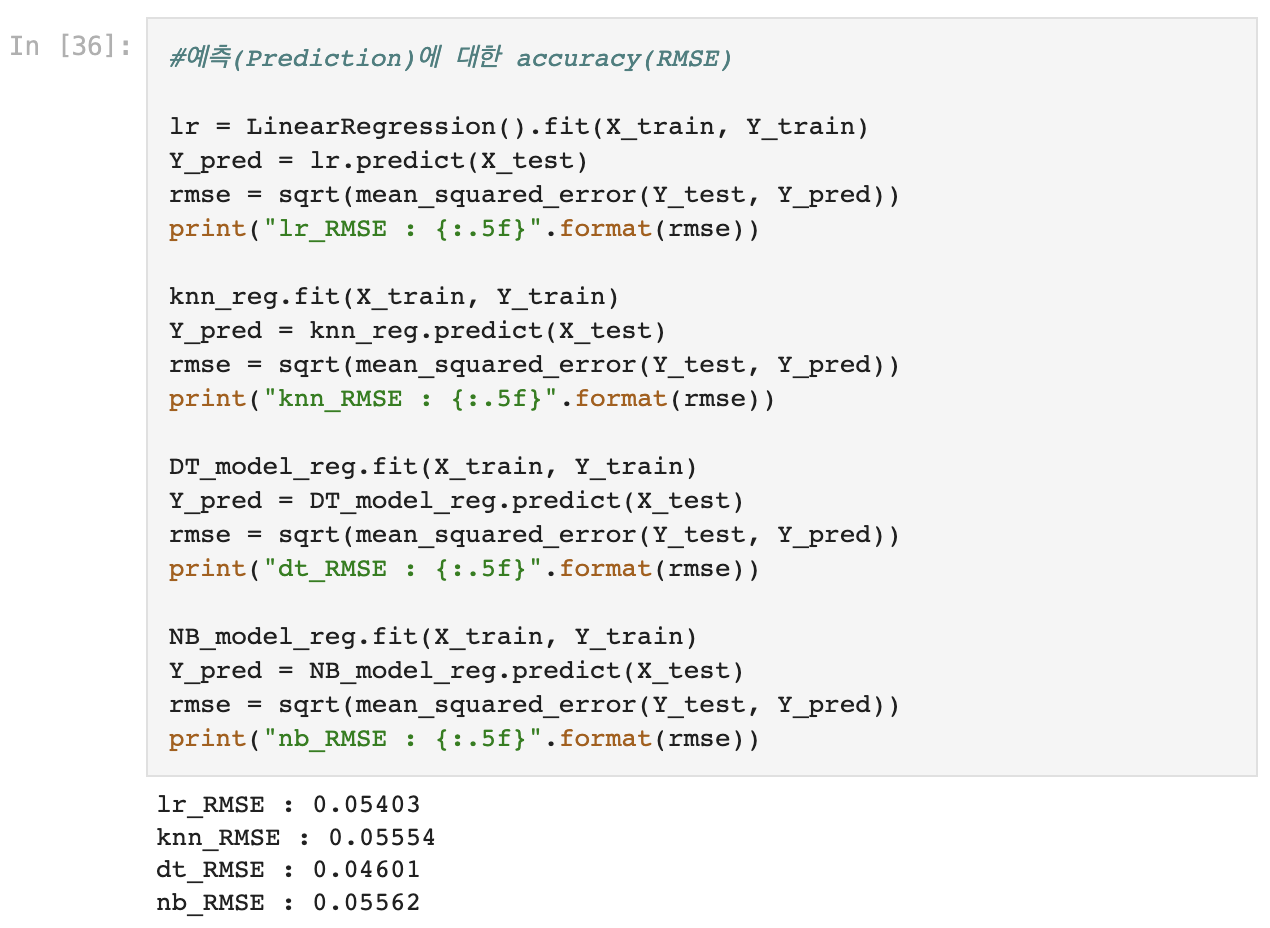
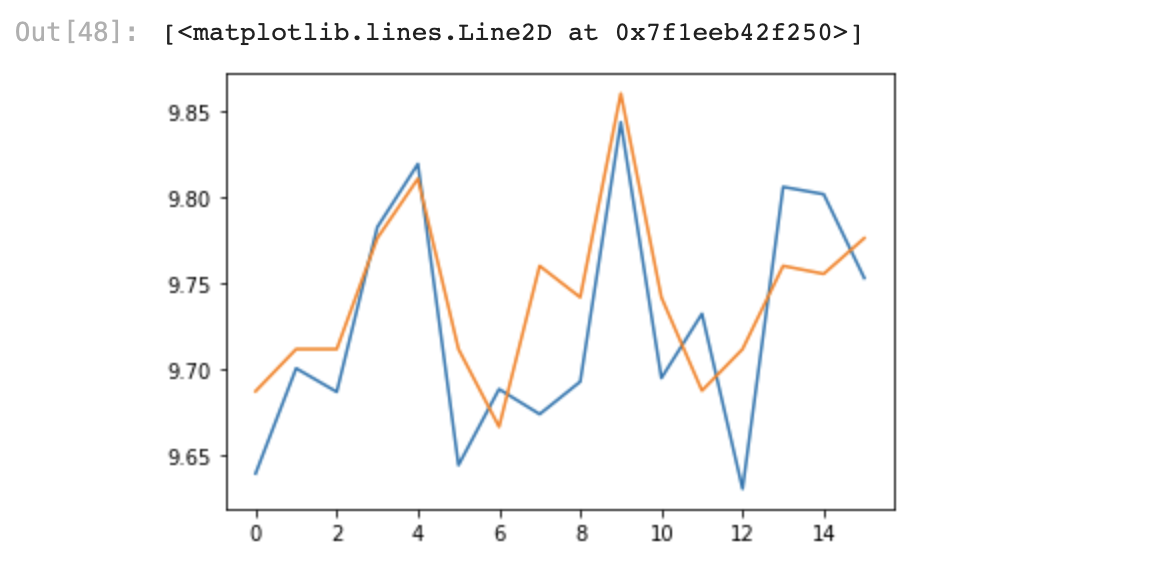
7. 모델 적용하여 실제값, 예측값 비교
- RMSE는 네 모델 모두 큰 차이가 없지만, accuracy는 Decision Tree가 압도적으로 높게 나왔다.
- DecisionTree모형 선택!

'Python > Small Project' 카테고리의 다른 글
| [Python]Galaxy Z Flip·Fold5 소비자 반응 수집(네이버 데이터랩, 빅카인즈 기사, 유튜브 댓글 크롤링&시각화) (1) | 2023.08.15 |
|---|---|
| [Python] 'RFM 분석'을 통해 VIP 고객 선정하기 (1) | 2023.03.31 |
| [Python]LG그램&뉴진스 YouTube M/V 댓글 크롤링 후 텍스트 마이닝 시각화 해보기 (10) | 2023.01.31 |
| [Python Data Analysis]선형 회귀분석을 통해 'BMI지수'에 영향을 주는 요소 알아보기 (0) | 2023.01.16 |