R 프로그래밍 기초 #1
1. 변수 타입 확인
a <- "hello"
a
typeof(a)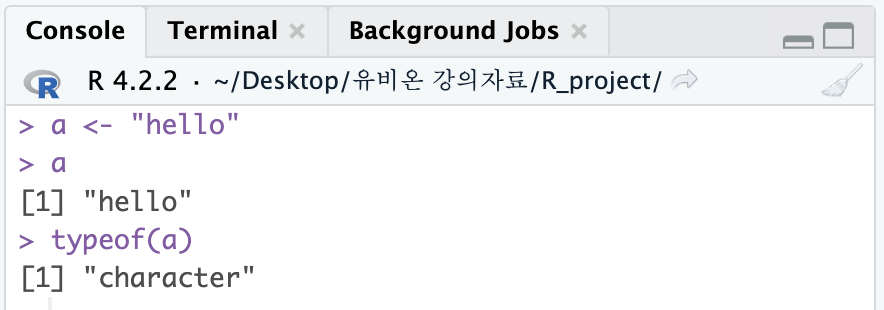
<-
- 변수에 데이터를 입력(할당)할 때 사용
cf) 파이썬: = , R: <-, = 모두 사용 가능
typeof()
- 괄호 안의 변수가 어떤 타입인지 알려줌
ex) a <- "hello"
typeof(a)
>>> "character"
2. 변수 타입 변환
a <- 1
typeof(a)
a <- as.integer(a)
typeof(a)
is.integer(a)
as.변수형()
- 강제 변수형 변환
ex) a <- as.integer(a) ⇨ a의 타입을 "double"에서 "integer"로 변환
typeof(a)
>>> "integer"
is.변수형()
- 변수형 확인
- 결과값 TRUE/FALSE로 출력
ex) is.integer(a) ⇨ a의 타입이 "integer"인가?
>>> TRUE
3. 연산
11%/%3 #몫 구하기
11%%3 #나머지 구하기
2**3 #제곱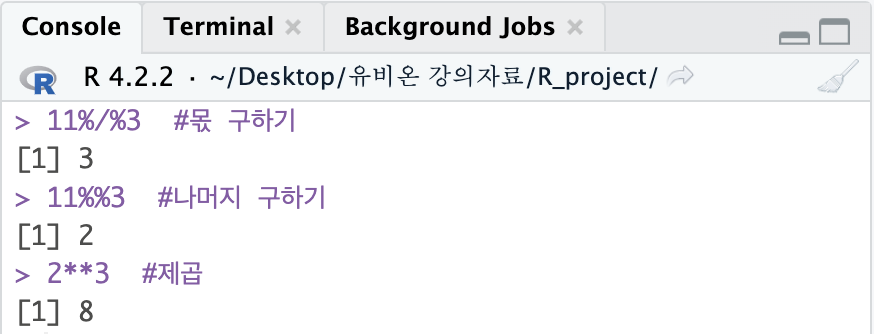
# 주석달기
- # 뒤에 작성한 내용은 실행되지 않음
%/% 몫 구하기
ex) 11 %/% 3 ⇨ 11 ÷ 3의 몫
%% 나머지 구하기
ex) 11 %% 3 ⇨ 11 ÷ 3의 나머지
** 제곱
ex) 2 ** 3 ⇨ 2의 3승
4. 패키지 설치
#패키지 (파이썬의 import)
install.packages("stringr")
library(stringr)
help("stringr")
??stringr

install.packages("패키지명")
library(패키지명)
- 패키지 설치
help("패키지∙함수명")
- help에 usesful links 자동으로 생성
??패키지∙함수명
- help에 Search Result 창 생성
5. stringr 패키지
#stringr 활용
#c: combine(리스트로 묶는다)
x <- c("why", "video", "cross", "extra", "deal", "authority")
print(x)
str_length(x)
str_c(x, collapse = ", ")
str_sub(x, 1, 2)
#문자열 세기(길이)
nchar(a)
str_length(a)
#str로 문자 join
a <- " "
a <- str_c(a, "abc")
#str로 공백 없애기
str_trim(a, side = "left")
#str 문자열 바꾸기
a <- "statistics"
a = str_replace(a, "tistics", "rbucks")
#str split
a <- "Sohyun Kim"
str_split(a, " ")
b <- "shooop24@daum.net"
str_split(b, "@")
str_length() 문자열 세기(길이)
str_c(a, "문자") a와 "문자" 합치기
str_trim(a, side = "left") 왼쪽 공백 없애기
str_replace(a, "", "") 문자열 바꾸기
str_split(a, "기준") "기준"으로 문자열 나누기
6. 벡터(vector)
#벡터(vector)
#c: combine, 합친다(묶는다)
#c를 통해 벡터가 만들어짐
a <- c()
a
b <- c(1,2,3,4)
b
c <- c("a","b","c","d")
c
d <- c(a,b,c)
d
c()
- combine, 합친다(묶는다)
-c를 통해 벡터가 만들어짐
b
rep(b,2) #변수b, 2번 반복
d
d[1] #변수 d의 인덱스1 출력
#R은 인덱스 1부터 시작(파이썬= 0부터 시작)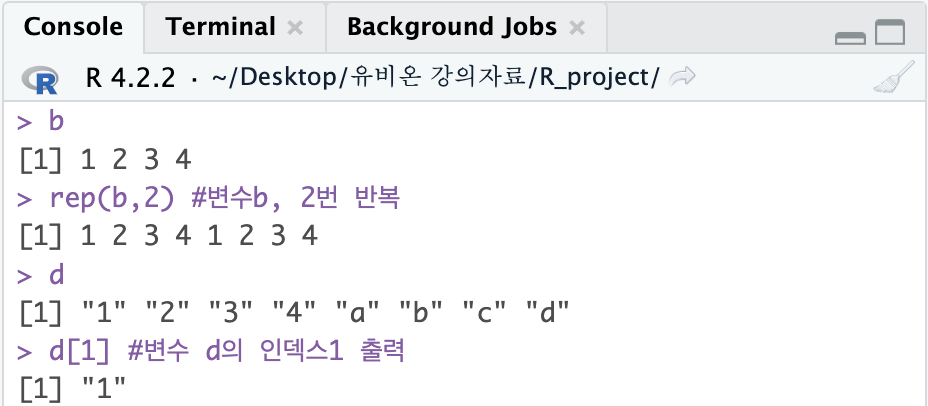
rep(변수, 반복횟수)
- 변수를 반복횟수만큼 출력
변수[인덱스번호]
- 변수의 인덱스 번호 값 출력
- R: 인덱스 번호 1부터 시작, 파이썬: 인덱스 번호 0부터 시작
a <- c(2, 3, 4, 5)
typeof(a)
a
a <- as.data.frame(a)
typeof(a)
a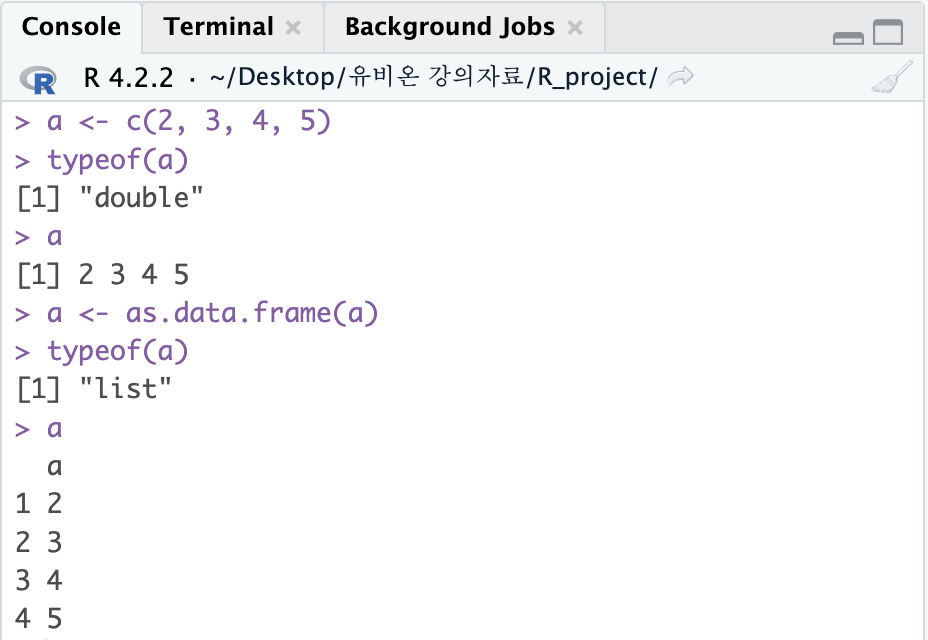
as.data.frame(변수)
- 리스트를 데이터 프레임으로 변환
- 타입: "list"
7. 문자열 합치기
#문자열 합치기
#head + tail
head <- "hello"
tail <- "world"
paste(head, tail, sep = " ")
paste(변수, 변수, sep = " ")
- 공백 " " 을 두고 변수와 변수 합치기
8. 대문자∙소문자 변환
#대문자로 바꾸기
a <- "Hello World"
a <- toupper(a)
a
#소문자로 바꾸기
a <- tolower(a)
a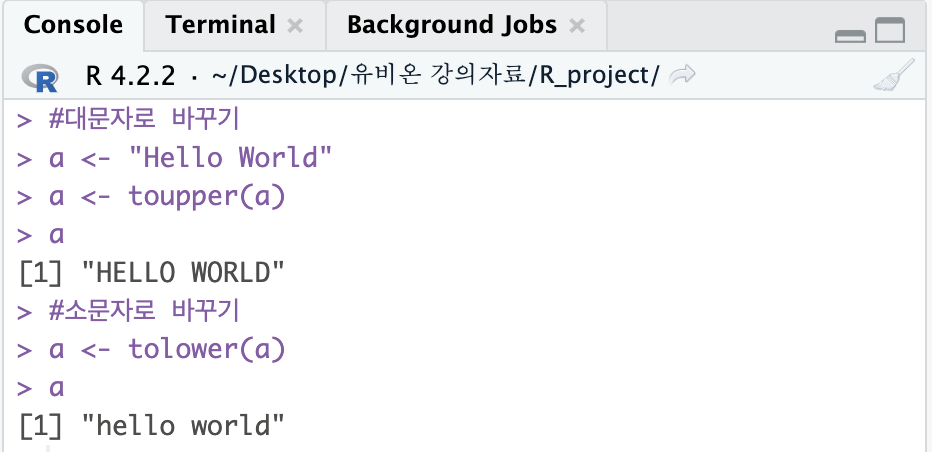
toupper() 대문자 변환
tolower() 소문자 변환
9. 논리형
#논리형(T, F)
a <- T
typeof(a) #logical=논리형(T or F)
is.logical(a)
a <- 12
typeof(a) #double= 숫자
is.logical(a)
a <- as.logical(a) #변수a가 12에서 True(logical)로 바뀜
typeof(a)
#Python: 집단형 X에 OneHotEncoder / R: as.factor(X)
a <- c(1,2,3,4,5)
typeof(a)
a <- as.logical(a)
typeof(a)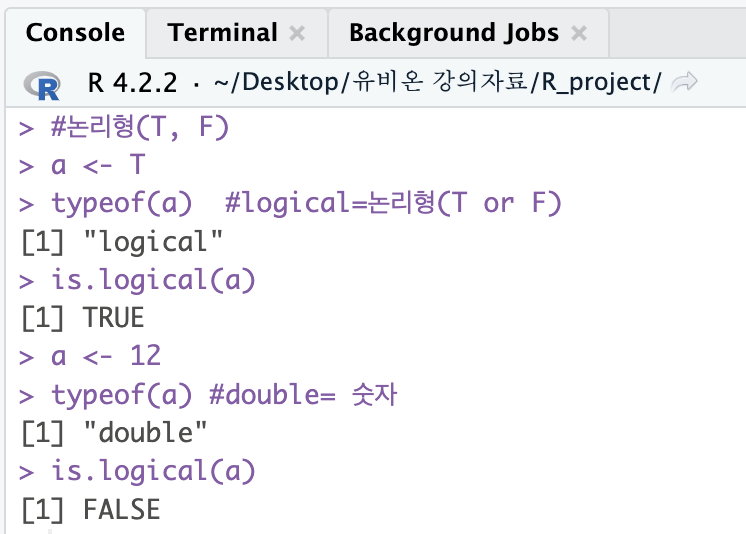
logical = 논리형 (TRUE or FALSE)
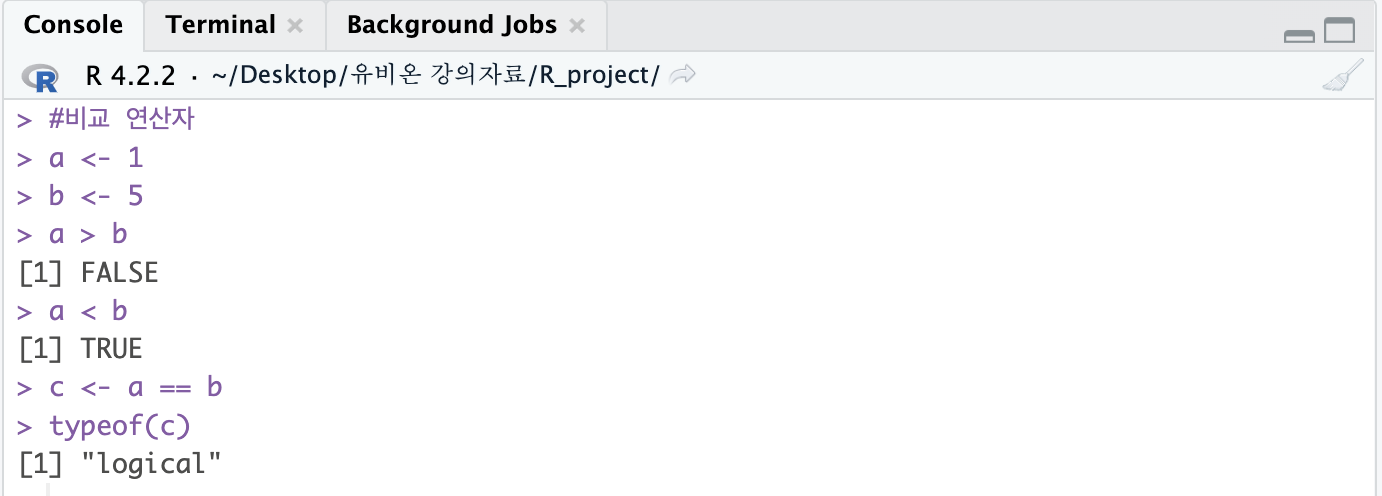
10. 비교 연산자
#비교 연산자
a <- 1
b <- 5
a > b
a < b
c <- a == b
typeof(c)