R 프로그래밍 기초 #3.
1. 특수값 (NA, NULL, Inf, NaN)
#NA, NULL(결측값)
a <- NULL
is.null(a)
typeof(a) #type= NULL
b <- NA
is.na(b)
typeof(b) #type= logical
c <- c(1,2,3,NA,NULL)
c <- as.data.frame(c)
is.na(c)
is.na(c$c) #c라는 데이터프레임 안의 변수(x)c열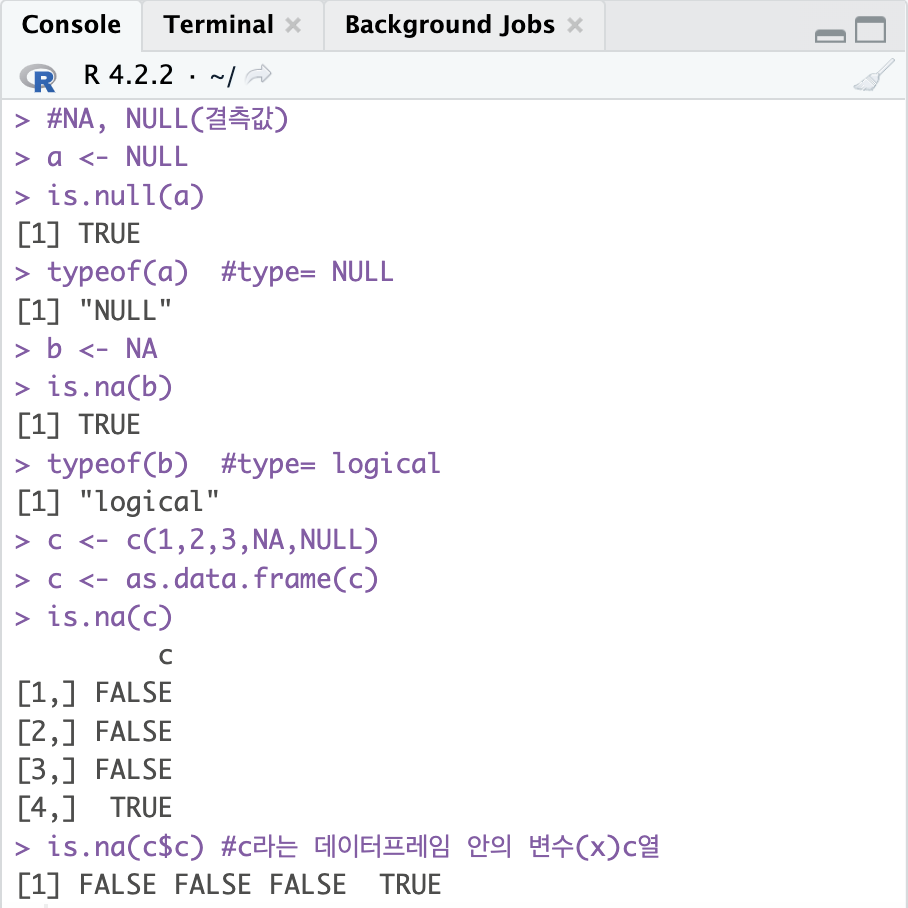
NULL의 타입 : 'NULL'
NA의 타입 : 'logical'

d <- 10/0
d #Inf
e <- -10/0
e #-Inf
f <- 0/0
f #Nan(없다)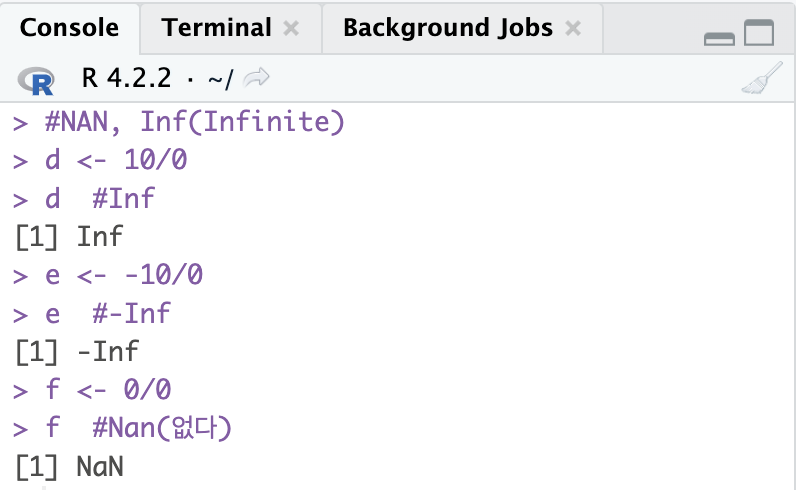
Inf : Infinte; 양의 무한대
-Inf : Infinite; 음의 무한대
NaN: Not a Number; 없다
2. 데이터 타입 변환
#데이터타입 변환
data <- c(1,2,3)
typeof(data) #double
d1 <- as.character(data)
typeof(d1) #character
d2 <- as.numeric(data)
typeof(d2) #double
d3 <- as.factor(data)
typeof(d3) #integer
d4 <- as.matrix(data)
typeof(d4) #double
d5 <- as.array(data)
typeof(d5) #double
d6 <- as.data.frame(data)
typeof(d6) #list

as.character() ⇒ 'character'
as.numeric() ⇒ 'double'
as.factor() ⇒ 'integer'
as.matrix() ⇒ 'double'
as.array() ⇒ 'double'
as.data.frame() ⇒ 'list'
3. 파이프연산자 (%>%)를 통한 iris 데이터 정제
#dplyr
install.packages("dplyr", dependencies = T)
library(dplyr)
dplyr : R의 기본적인 data.frame에서 자료를 조건에 따라 선택하고, 배열하고, 결합하고, 요약하는데 편리한 함수을 제공하는 패키지
#파이프 연산자를 통한 정제
# %>% : 단축키 'ctrl + shift + m'(Window) / 'command + shift + m'(Mac OS)
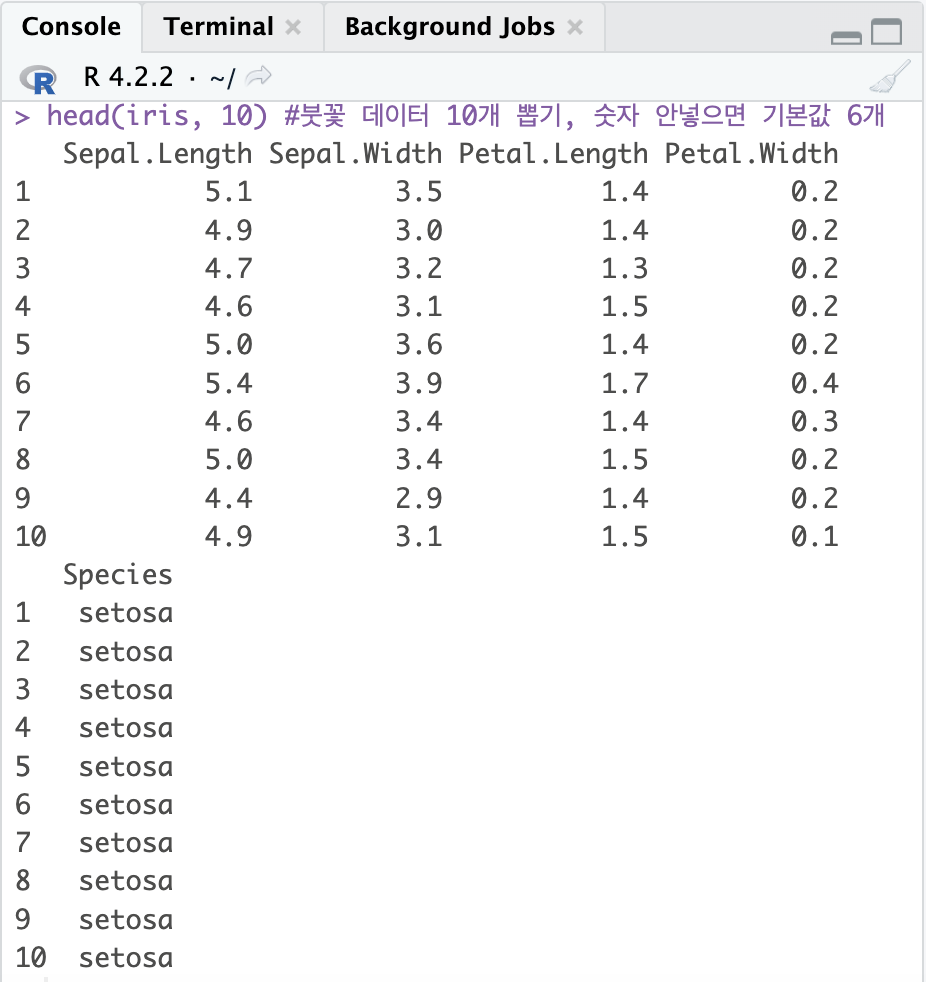
head(iris, 10) #붓꽃 데이터 10개 뽑기, 숫자 안넣으면 기본값 6개
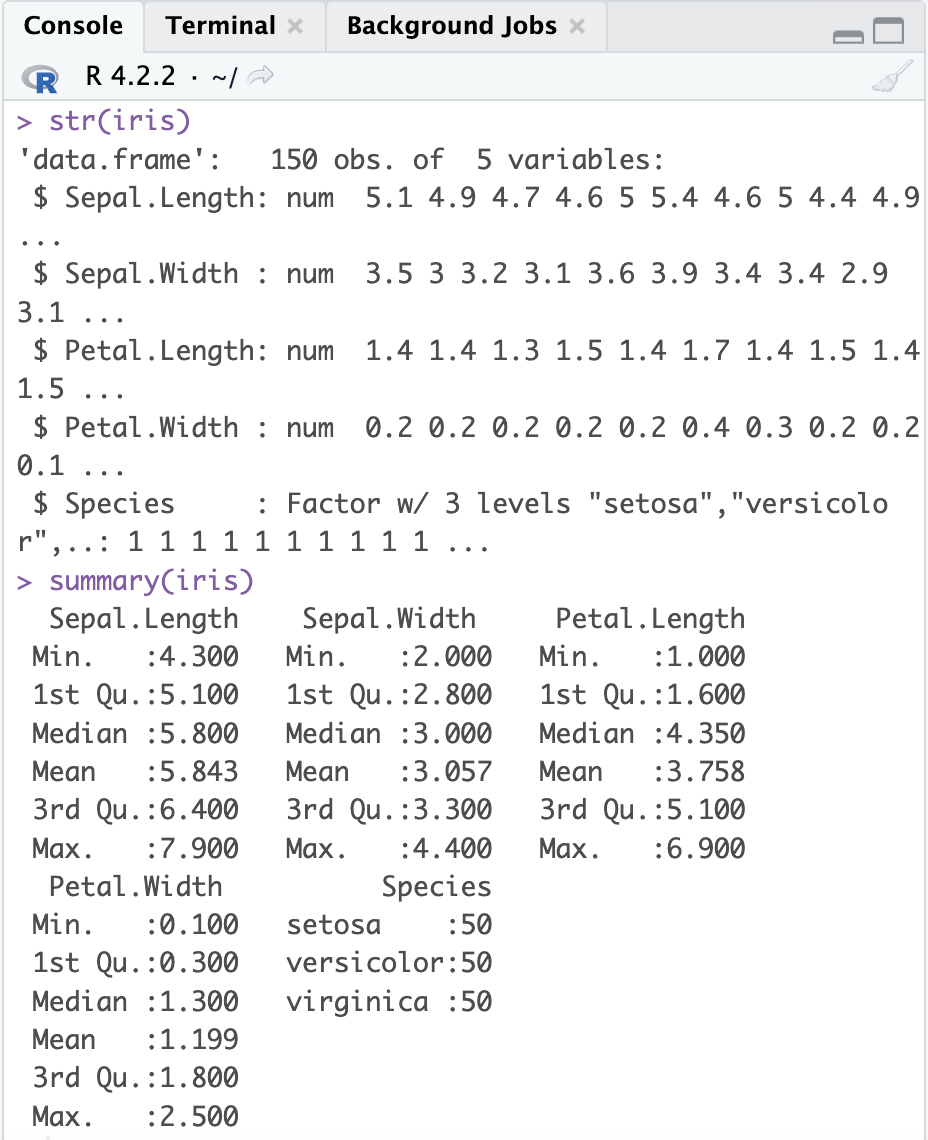
str(iris)
summary(iris)
iris <- data.frame(iris)
View(iris) #데이터프레임 창 보기
iris(붓꽃) : 이 유명한(Fisher's 또는 Anderson's) 홍채 데이터 세트는 3종의 홍채 각각에서 50개의 꽃에 대한 변수인 꽃받침 길이, 너비, 꽃잎 길이 및 너비의 센티미터 단위로 측정값을 제공합니다. 그 종은 아이리스 세토사, 버시컬러, 그리고 버진리카이다.
파이프연산자, Pipe Operator (%>%)
- 동일한 데이터를 대상으로 연속으로 작업하게 해주는 오퍼레이터(연산자)
- 데이터 세트 %>% 조건 또는 계산 %>% 데이터 세트
- 함수를 연달아 사용할 때, 함수 결과값을 변수로 저장하는 과정 필요 없음
- 단축키 : Ctrl + Shift + M (Windows) / Command + Shift + M (Mac OS)
① 조건(filter)걸기, 선택한 열의 데이터만 확인
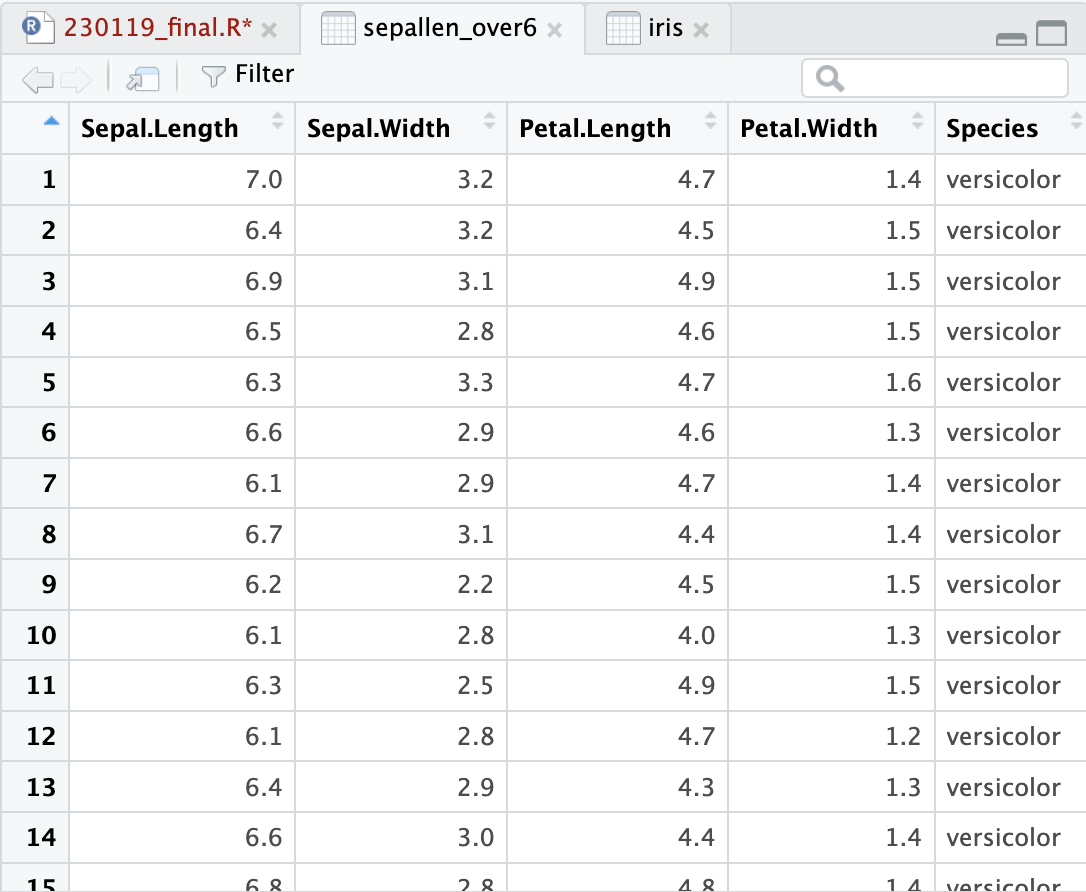
#filter: 조건 걸기_Sepal.Length가 6을 넘는것만 뽑기
sepallen_over6 <- data.frame(iris %>% filter(Sepal.Length>6))
View(sepallen_over6)
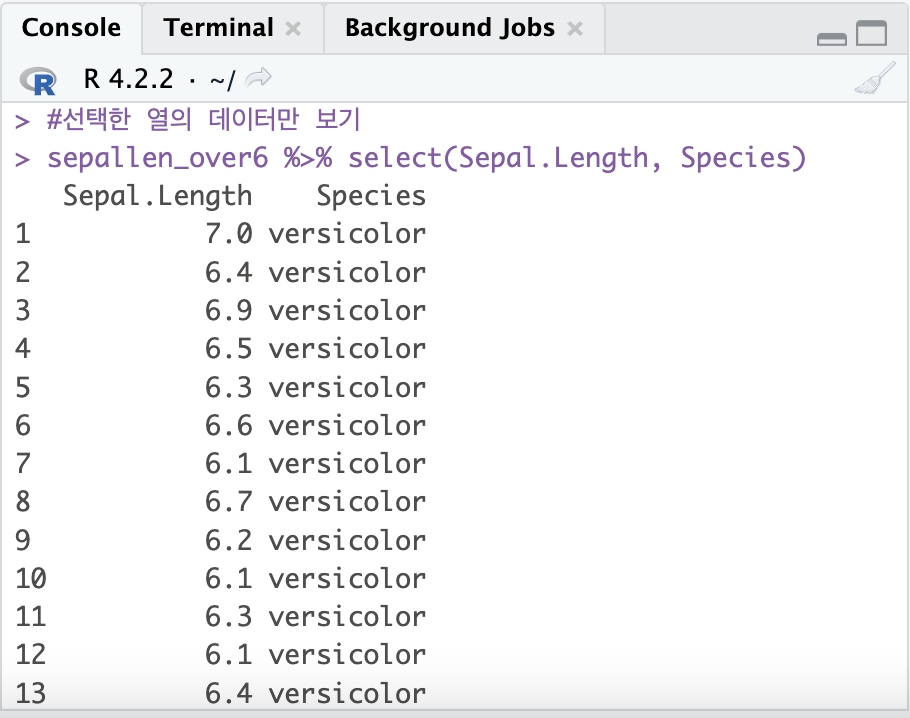
#선택한 열의 데이터만 보기
sepallen_over6 %>% select(Sepal.Length, Species)
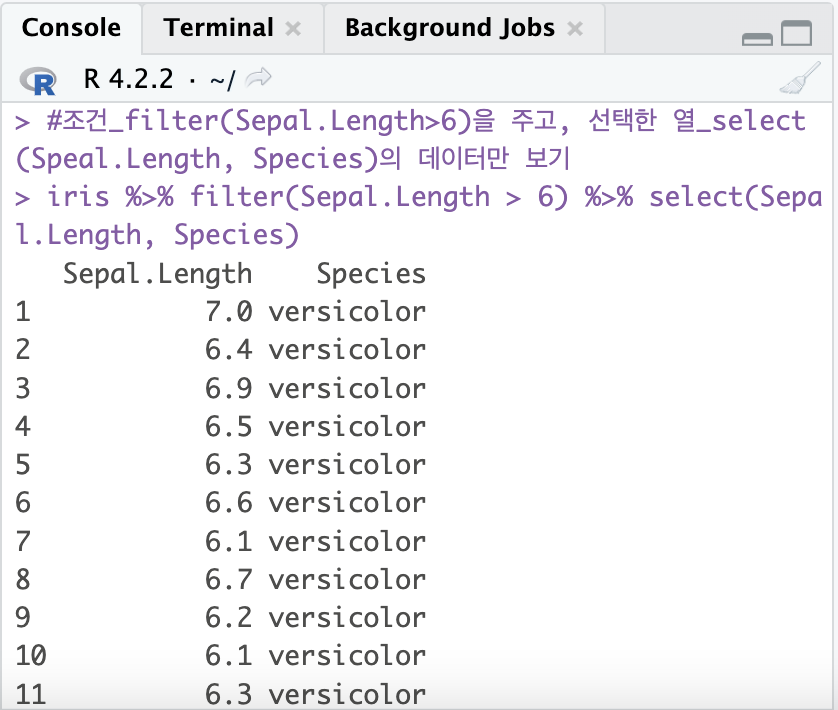
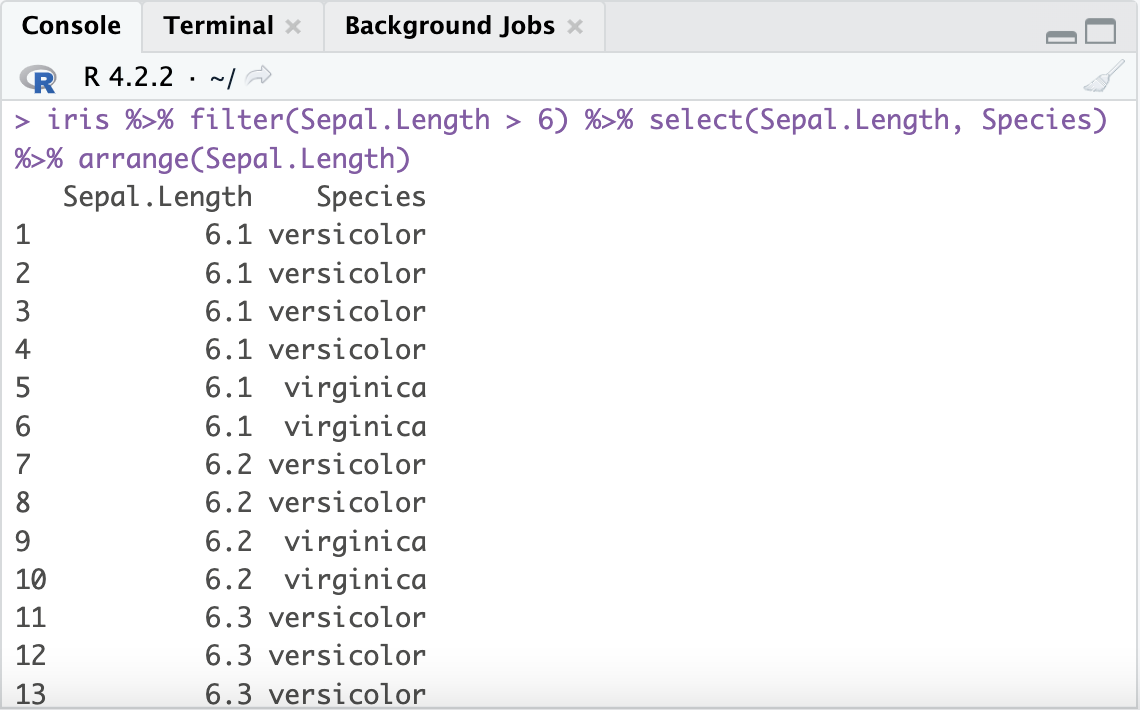
#조건_filter(Sepal.Length>6)을 주고, 선택한 열_select(Speal.Length, Species)의 데이터만 보기
iris %>% filter(Sepal.Length > 6) %>% select(Sepal.Length, Species)
② 오름차순 정렬, 상위∙하위 n개 데이터 추출, 그룹화
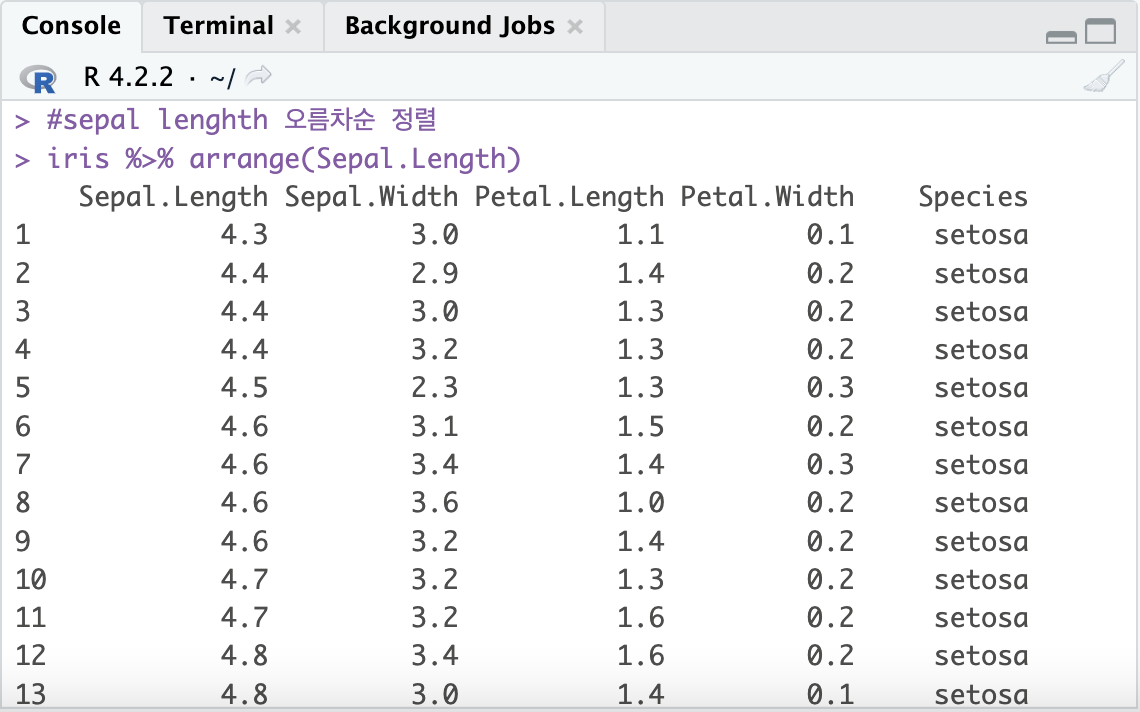
#Sepal.Length 오름차순 정렬
iris %>% arrange(Sepal.Length)
iris %>% filter(Sepal.Length > 6) %>% select(Sepal.Length, Species) %>% arrange(Sepal.Length)
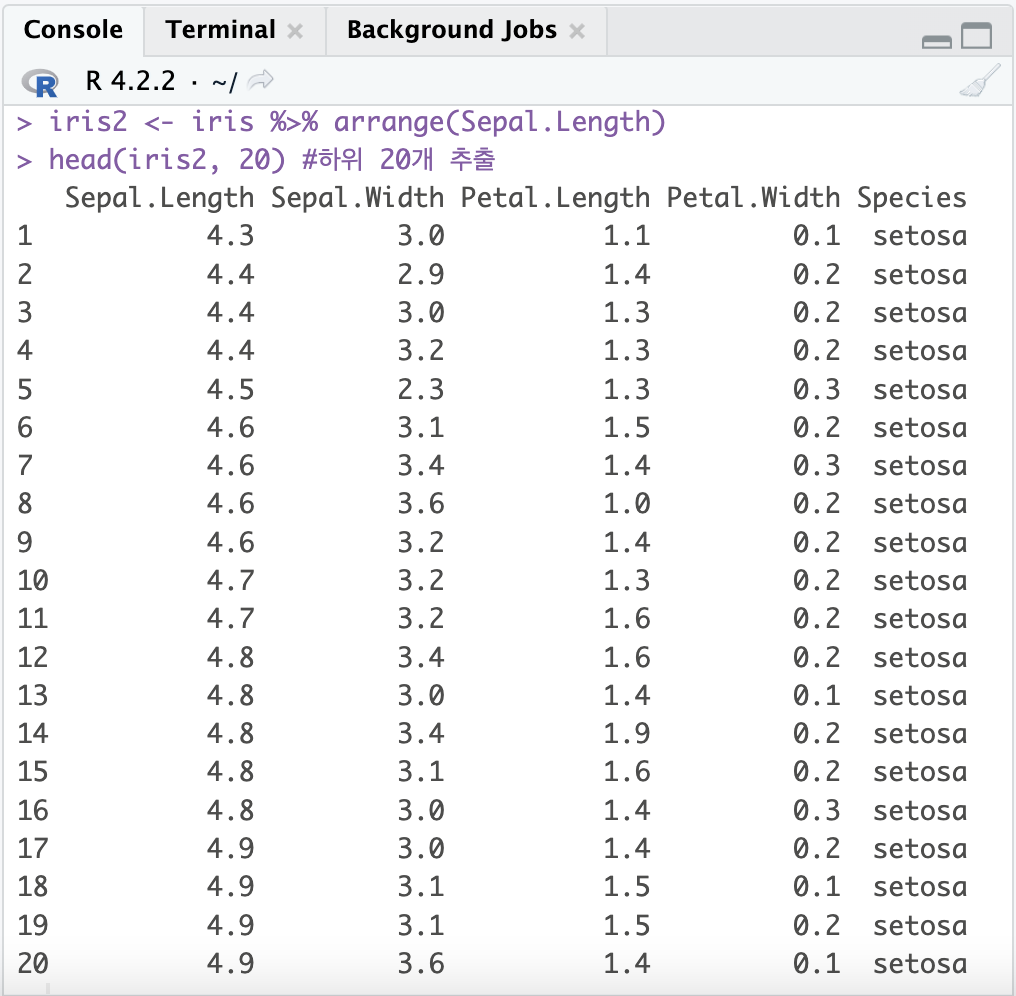
iris2 <- iris %>% arrange(Sepal.Length)
head(iris2, 20) #하위 20개 추출
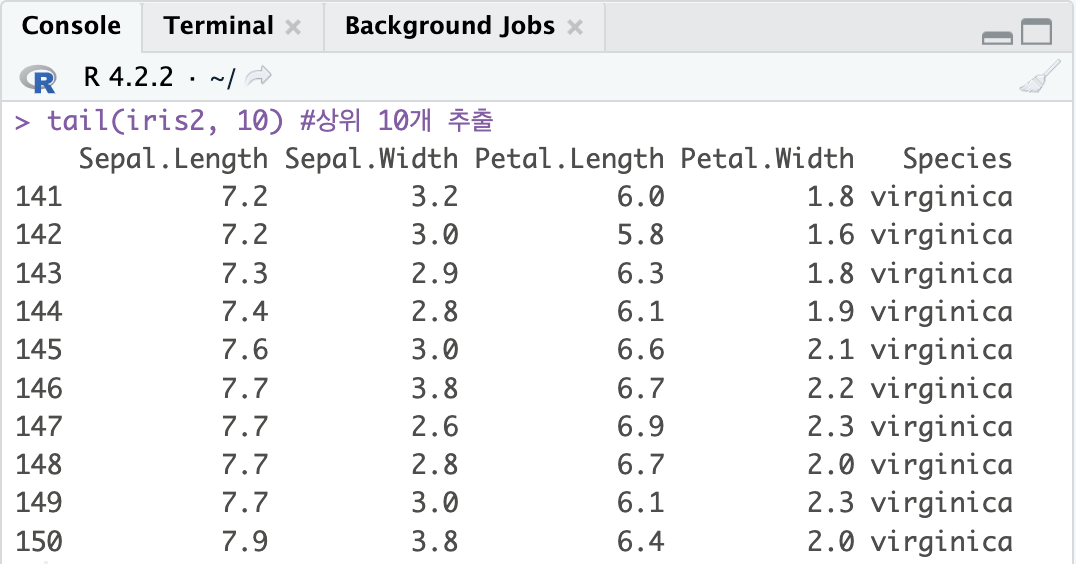
tail(iris2, 10) #상위 10개 추출
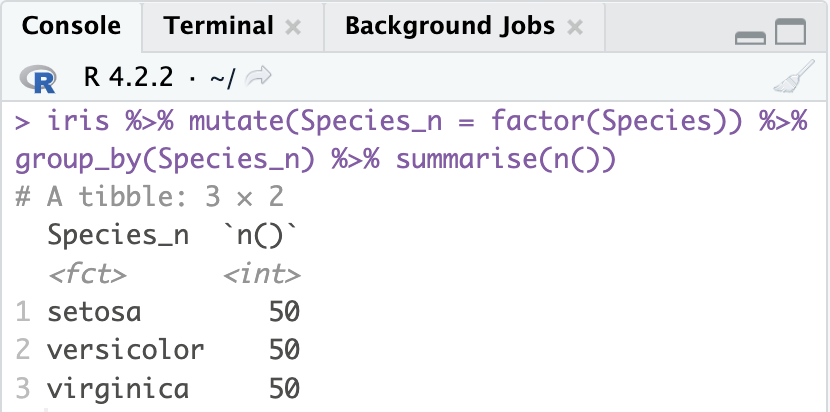
#Species_n 변수를 기준으로 그룹화, 각 그룹별로 관측치 개수를 계산하여 요약한 결과 반환
iris %>% mutate(Species_n = factor(Species)) %>% group_by(Species_n) %>% summarise(n())
??mutate #복제
mutate() : 기존 변수의 함수인 새 열 생성. 또한 이름이 기존 열과 동일한 경우 열을 수정, 열 값을 NULL로 설정하여 열 삭제 가능