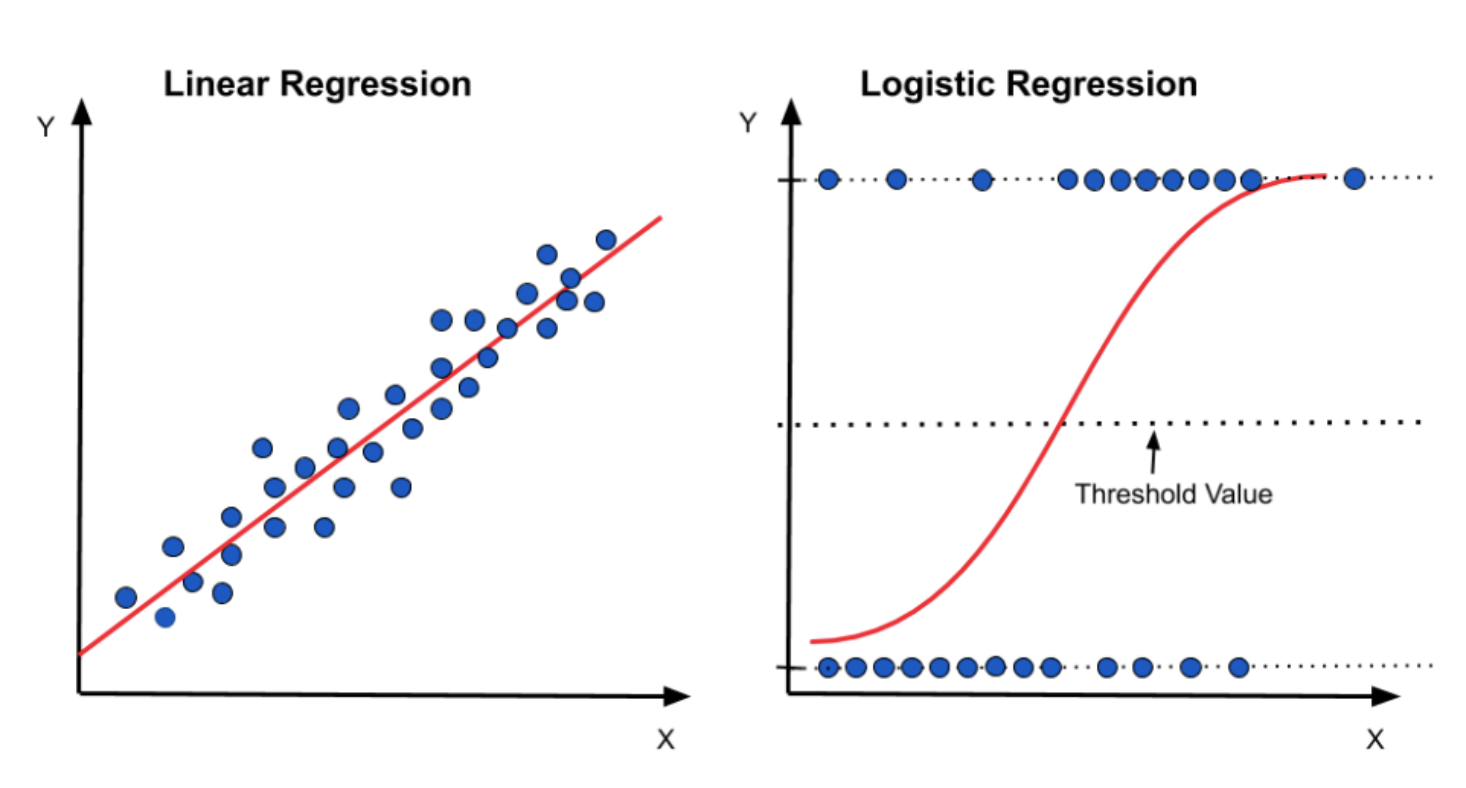
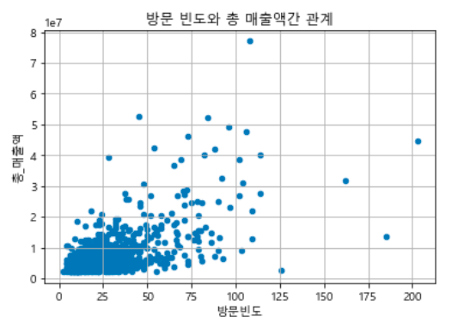
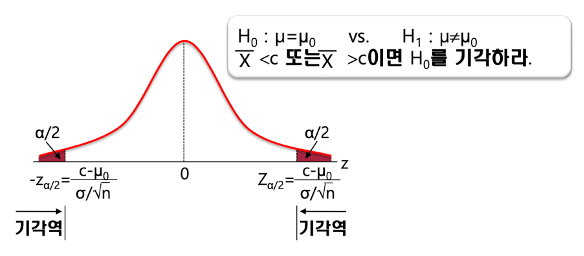
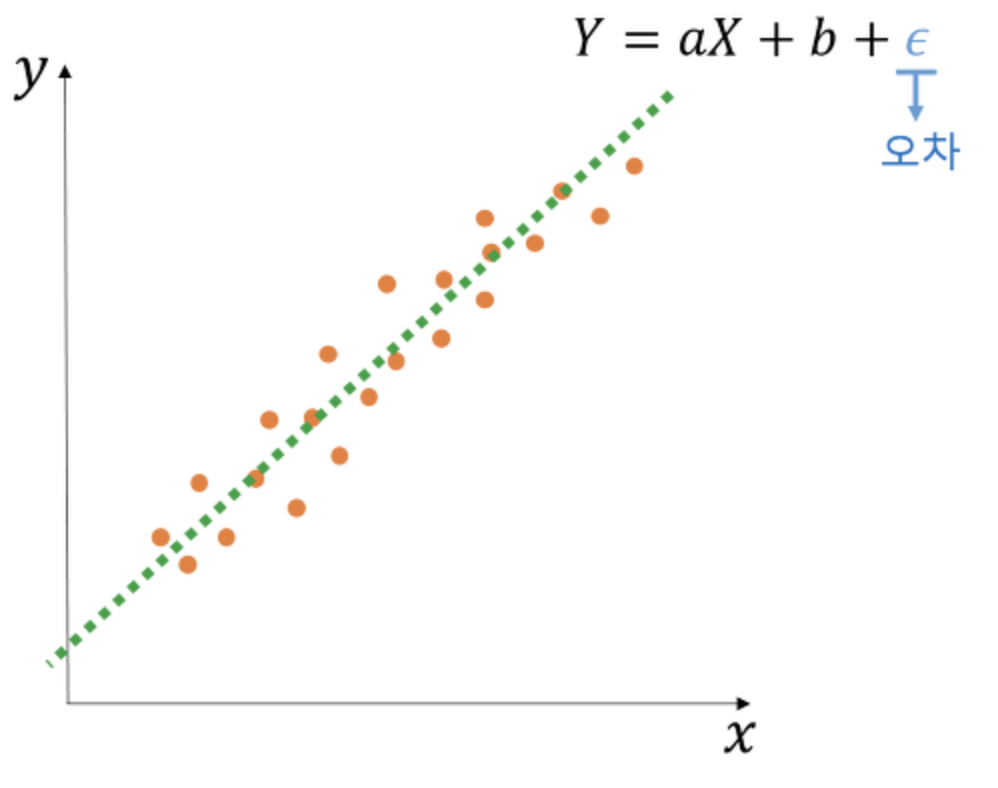* K-최근접 이웃(K-NN; K-Nearest Neighbor) - 가장 근접하게 있는 데이터 종류에 따라서 해당 데이터의 종류를 정해주는 알고리즘 (유유상종) - 판별하고 싶은 데이터와 인접한 k개의 데이터를 찾아, 해당 데이터의 라벨이 다수인 범주로 데이터를 분류하는 방식 - k는 '홀수'로 하는것이 좋음. 짝수일 경우 동점 상황이 만들어져 분류할 수 없는 경우가 발생할 수 있기 때문 * K-NN 코딩하기 1) KNeighbors Classifier(분류형) - 순서: 데이터 분할 - 데이터 표준화 - 데이터 밸런싱 - 모델 생성 - 모델 적용 - 결과값 도출 - X는 이산형 변수만 가지고 있기 때문에, StandardScaler()만 적용 - 오버샘플링 SMOTE 적용 - knn 분류모델 생성: ..